

Providing Disaster Recovery for Horizon
Disaster Recovery in Horizon Design
Omnissa Horizon 8 and Omnissa Horizon Cloud Service provide a desktop and application virtualization solutions that enable organizations to deliver virtualized desktop services and applications to end users. Because organizations depend on Horizon to deliver key services to users, the design of the Horizon services must provide disaster recovery (DR) capabilities to ensure availability, recoverability, and business continuity.
Disaster recovery for Horizon workloads should be viewed from the perspective of the users. Where a user is being delivered Horizon-based desktops or published applications from a particular location, contingencies should be made to provide equivalent services from a separate location.
Simplify Disaster Recovery with Horizon
Disaster recovery plans need to include the ability for users to access desktops and applications. With physical desktops, this was often planned on the assumption that the users could work from another office location, either owned or leased, that had been primed for them. That secondary location would provide replacement imaged physical devices. Times and challenges have changed, and the assumption that users can access an office location no longer holds true. The focus is now on how to provide both continuity for the user, as well as business continuity for the IT systems. When planning for user access, a remote-first approach must now be taken.
A remote-first approach that relies on physical desktops is challenging and introduces many operational and security concerns. Providing disaster recovery for physical desktops is difficult, especially when combined with the need for the flexibility of a remote-first experience.
By contrast, Horizon allows flexibility for providing disaster recovery to desktops and the applications.
- Horizon is designed to allow users a remote and roaming experience, where they can access their desktop and applications from any device in any permitted location.
- Horizon abstracts the desktop from the physical device. This allows the components that make up a user’s desktop and data to be replicated to alternative data centers or locations to provide site resiliency and disaster recovery.
- Horizon offers multiple deployment options, from on-premises data centers to running in a variety of cloud platforms. This offers flexibility with regard to the consumption model and choice about the location of recovery services.
Purpose of This Guide
Whether you have already deployed Horizon, or you are looking at deploying Horizon, it is important to understand, plan, and design for a Horizon environment that is resilient at all levels, including the ability to deliver disaster recovery to protect against site or location outages.
This guide covers the considerations and discusses how to approach providing disaster recovery for Horizon-based workloads, including:
- Strategy and approach
- Available deployment options for recovery locations or sites
- Ways in which the resources from multiple Horizon environments can be presented to the user
- Considerations for making user applications and data available in the recovery location
- Considerations when enacting disaster recovery and failing over to the recovery site
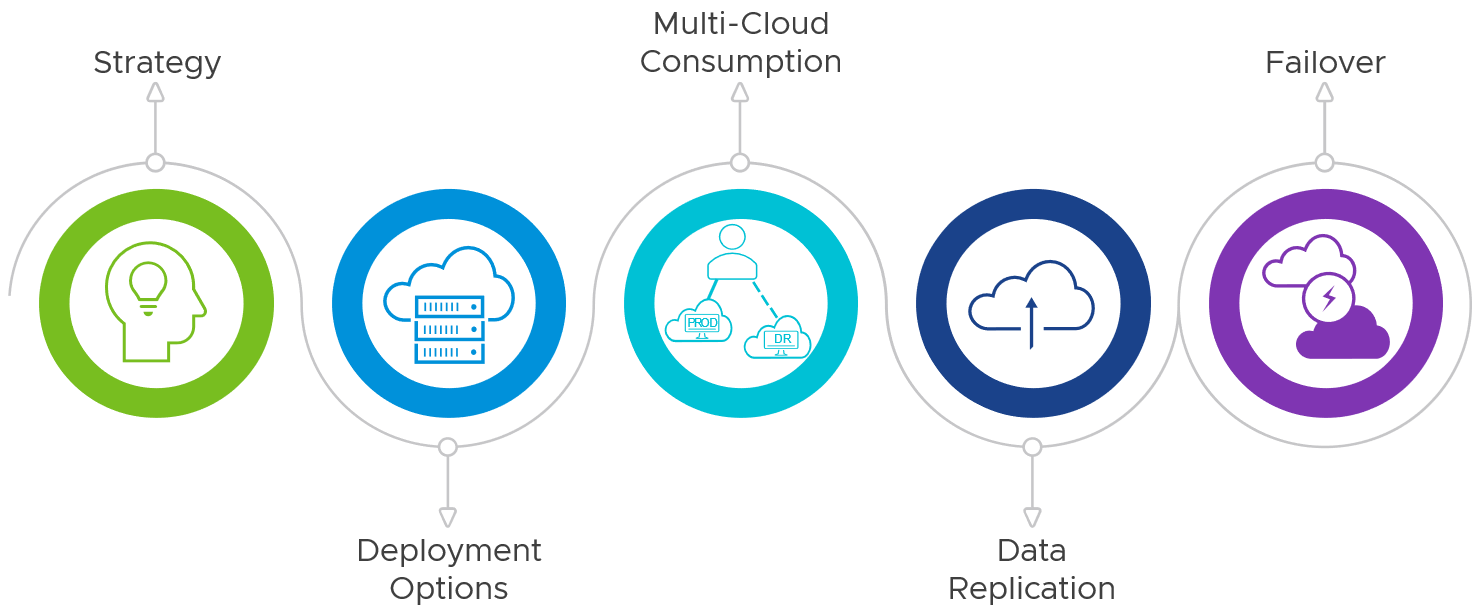
Figure 1: Disaster Recovery for Horizon
Although outside the scope of this document, consideration should also be given to business continuity of enterprise applications, databases, and other systems that users will require access to when using their Horizon resources during a DR event.
To understand the terms used throughout this guide see the Glossary of Terms at the end of this document.
Hybrid, Multi-Cloud Consumption Strategy
Many choices and decisions must be made about how to approach disaster recovery, what kind of service to offer to users, and what data to replicate and reproduce. Horizon offers many deployment options for a hybrid consumption of resources to provide both expansion and disaster recovery capabilities.
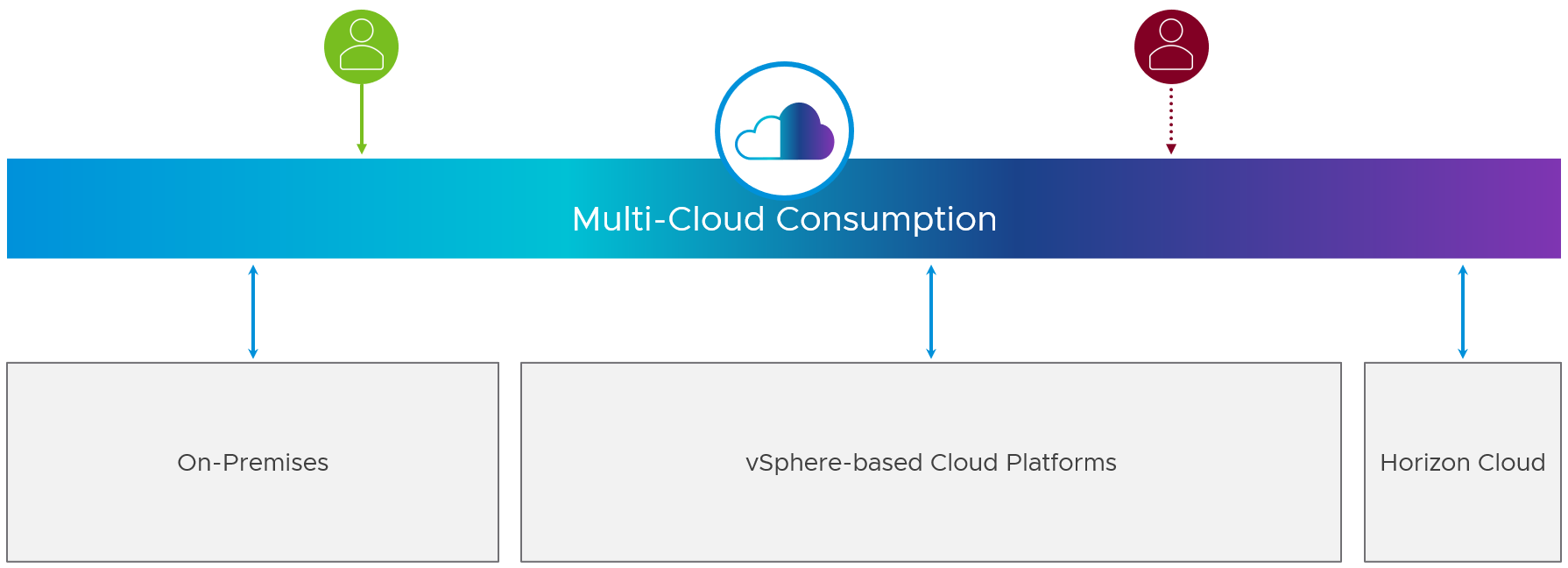
Figure 2: Multi-Cloud Consumption Strategy
User-Based Perspective
The kind of service delivered from a DR site should be driven by the requirements of the users and the business, balanced with any limitations or cost restrictions. At a high level, DR for Horizon consists of offering users an equivalent service (desktops and published applications) from an alternative site or location. For example:
- Users are normally serviced from site 1 at location A.
- In a disaster recovery event, users will be delivered an equivalent service from site 2 in location B.
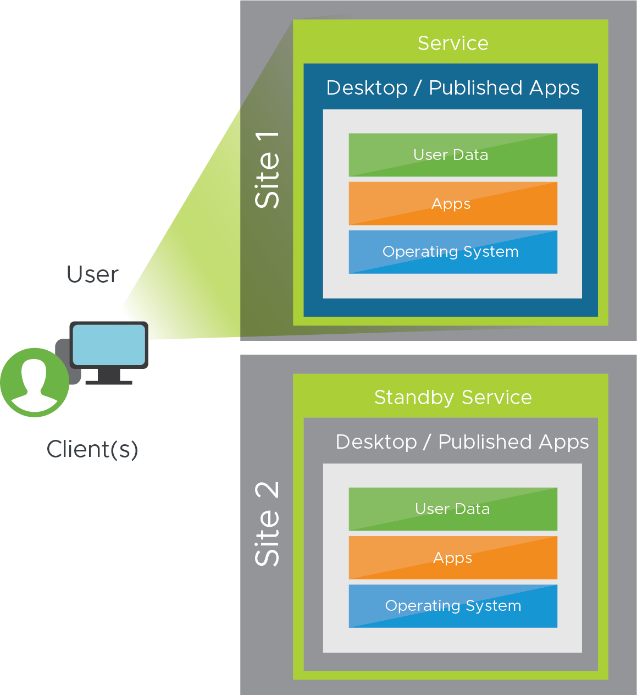
Figure 3: Equivalent Horizon Resources Available from a Second Site and Location
Geographical Considerations
When designing a disaster DR solution, choosing a geographical location involves many considerations and has many implications, including:
- Safe distance, to ensure that the DR site is far enough away from the production location to be unaffected by any geographic disasters such as storms or flooding
- Connectivity, so that the DR site can adequately service your users in the event of an outage
- Security and monitoring
- Cost of ownership
Single Site
Each individual Horizon environment should be built to be highly available from a user’s point of view. High availability is achieved by implementing redundancies and leveraging platform-based functions to service end users in accordance with their expectations. This ensures that the service can still be delivered from that location, even in the event of single-component failures. But even though a single-pod deployment of Horizon might be highly available, it cannot, by itself, provide a DR solution.
If you implement a second Horizon pod in the same site, you can configure the pods to work together to provide users with an always-on experience of service. You can leverage global entitlements with Cloud Pod Architecture or multi-cloud assignments with Horizon Universal Broker, as is discussed later in this document, in the section How Horizon Users Leverage Multi-Cloud Resources.
Although deploying multiple pods in a single geographic locality might provide a more highly available service, it typically does not protect against local disasters. For example, if the recovery site is located within the same building, site, or power grid, or is serviced by the same local Internet facilities, it is likely not suitable as a recovery site. A good disaster recovery site should not share any single point of failure with the primary, or production, site.
Multiple Sites
Just as you can deploy multiple pods in a single site, you can also configure pods in multiple sites to work together to provide users with a cohesive experience. Horizon can be implemented in various types of multiple-site deployments and can be presented to end users as a single way of consuming.
The primary benefit of a multiple-site deployment is that you have alternate sites that can service users in the event of a disaster for a given site. In multiple-site deployments, the production site or sites contain the Horizon deployment that users access as a part of their normal activities, whereas alternate sites contain information and applications that are built from the primary repository information. Similarly, to deploying multiple pods in a single site, you can also configure pods in different sites to work together to provide users with a cohesive experience.
For the examples that follow, we assume that multiple-site deployments are geographically distanced from each other to reduce the risk of a disaster effecting both locations.
Types of Sites or Deployments
Another decision that you need to make is the purpose and state of readiness of each individual deployment of Horizon. Will the DR location and the Horizon deployment in it be fully functional and running at full scale, or will it be running a minimal infrastructure that can be scaled up during a recovery event?
Factors to consider include the cost of the recovery site, both during normal operations and during a DR event. The type of recovery deployment chosen has an impact on the recovery time objective (RTO)—how long it takes to bring the system back online—and, potentially, the recovery point objective (RPO)—how much data the business can afford to lose, such as 10 minutes, one hour, or one day of data.
For example, in the event of using a cold recovery site, what number of users would be impacted during the time it takes to bring the cold site online? What would be the revenue loss or other impact to the business as a result of this downtime?
Table 1: Recovery Site Types and Considerations
| Recovery Site Type | Cost | RTO | RPO |
| Cold | Low | Long | Long |
| Pilot Light | Medium | Medium | Medium |
| Live | High | Short | Short |
Other factors to consider include complexity of failover processes, capacity planning, and the tasks that will need to be carried out to enable the recovery site in the event of an outage.
Cold Site
A cold site is equipped with appropriate infrastructure components and with adequate space that allows for the installation or buildout of a set of systems of services by the key staff required to resume business operations. This type of site might consist of core components, such as Horizon 8 Connection Servers, that are normally powered off. During an outage the servers would need to be powered on, additional servers built to scale out for capacity, and pools of virtual desktops and farms of RDSH servers created to provide services for users.
Pilot-Light Site
The term pilot light refers to a small flame that is always lit in devices such as gas-powered heaters and can be used to start the devices quickly when required. Relative to disaster recovery, a pilot-light environment contains all the core components of a distinct system or service, and it is adequately maintained and regularly updated. The implementation is always on and is built to functional equivalency of the production site.
In a pilot-light site, user-based desktop and applications resources are kept at minimal levels for standard operation. When a disaster event is declared, the relevant IT teams are directed to add additional capacity. This implementation allows you to restore a system at an effective scale quickly and efficiently. Scaling up the DR environment might include:
- Acquiring more hardware hosts or capacity
- Adding more components, such as Horizon Connection Servers, to increase the scale and throughput capability
- Increasing the size of desktop pools or RDSH server farms
When utilizing a Software-Defined Data Center (SDDC)-based cloud platform during normal operations, you can choose to keep a small host footprint in the recovery location where you will deploy your Horizon instance. An important consideration for DR then becomes host availability in the cloud platform and the ability to increase the resources available to your recovery environment.
Live Site
You can opt to have a DR environment that is fully built and scaled out so that it is ready to service users in a recovery event with minimal effort or intervention. In many cases, it makes sense to utilize both the original production environment and this new recovery environment during normal operations, by servicing different groups of users from both locations.
In this type of implementation, each site is accessed by users regularly and is always live. Users are typically spread among each implementation based on location (nearest location or specific site is designated as the default for that user), and users may use other sites in the event of an outage or disaster. When both sites are actively used during normal operations, users should be assigned a default site. This makes operational challenges such as replication of data more manageable.
For example:
- Users in group A are normally serviced out of site 1 at location A and can be failed over to site 2 at location B.
- Users in group B are normally serviced out of site 2 at location B and can be failed over to site 1 at location A.
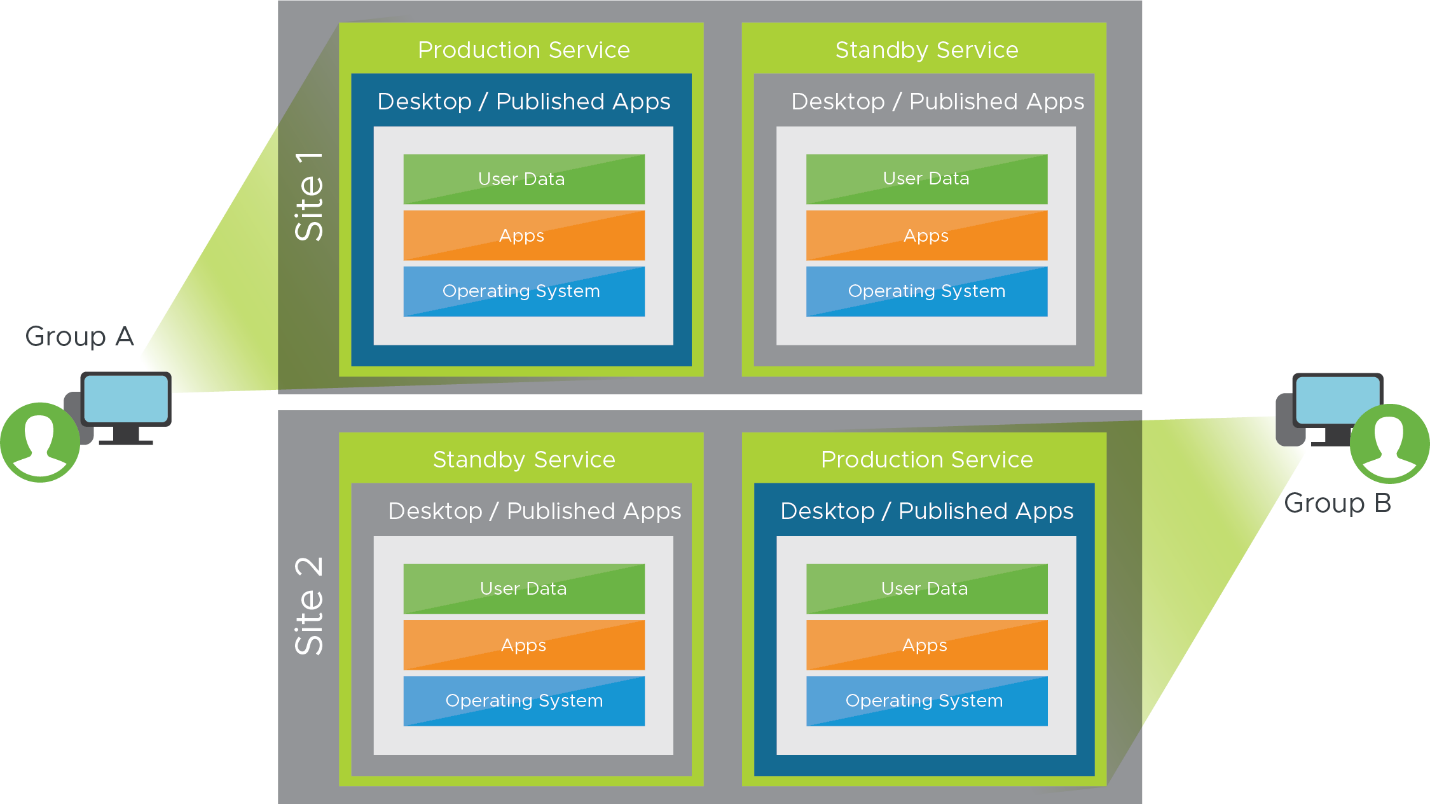
Figure 4: Horizon in Two Sites with Active Users in Both Sites
Increasing Capacity
Although spare hosts and capacity are usually available that can be used to expand your recovery site, depending on your RTO (recovery time objective) and growth requirement, you might not be able to reach your target number right away. The only way to guarantee the number of hosts you need right away is to reserve them ahead of time, but the trade-off is increased cost.
Note: Different platforms have varying expansion capabilities. New hosts in the same cluster might be created serially or in parallel, while hosts in different clusters are usually created in parallel. Investigate and understand how the selected platform provisions new hosts and whether faster host availability might be achieved by using more clusters.
Carry out tests to understand the time required to acquire capacity, add more components, and provision additional desktop clones or RDSH server clones.
When using Horizon Cloud Service, consuming Azure capacity, you need only request additional VM capacity from Microsoft (see Standard quota: Increase limits by region) and once granted, you can expand your deployment. With a native Azure implementation, Microsoft is responsible for maintaining the proper amount of hardware capacity to support the demands of the workloads in any given region.
Work with your sales representative to ensure that you will have adequate DR capacity when you need it.
Segmenting Use Cases
For most organizations, it is overly burdensome to provide like-for-like functionality in the event of a disaster. Maintaining duplicate copies of all possible systems might be an impossible task. For practical purposes and to reduce cost, many organizations decide that they will provide limited or reduced functionality for users in the event of a disaster.
User Prioritization
Segment end-user populations into tiers in terms of RTO. Some user segments might require a recovery desktop right away or within a very short period. For these user segments, you might have recovery desktops created and on standby for them. Other user segments might be able to tolerate a longer RTO and might require a recovery desktop only after a longer period.
Also consider what basic functionality must be recovered and by when for each of the user segments. Do you need to recover all the functionality or just offer the core apps and data that are considered essential? With some user segments, you might restore additional functionality over a longer period.
By segmenting and prioritizing users, and deciding when and what functionality is needed, you can plan for recovery of essential services and time the phased recovery of others, if required. This approach allows for flexibility in capacity planning and gauging the time it takes to acquire new hosts and provision additional Horizon desktops.
Segment by Horizon Resource Type
The types and purposes of Horizon clones can affect how you decide to reproduce the service in the recovery location.
- Nonpersistent desktops and published applications – Data and user configuration is extractable from the desktop.
- Full clones – Might contain user configuration and data, which cannot be extracted.
Nonpersistent Desktops and Published Applications
Unlike traditional DR solutions for server applications, where replication of all data from the production site to the recovery site is needed, we recommend a different approach for Horizon when using nonpersistent desktops or published applications. Nonpersistent desktops and published applications use stateless virtual machines that can be created and recreated very quickly. It does not make sense to replicate these VMs across sites.
Separate Horizon pods can be deployed on a variety of platforms, and users can be entitled to both the production and DR versions of their Horizon resources. Using Universal Broker, Workspace ONE Access, or Cloud Pod Architecture can assist in making this easier for users and give them a better experience.
You will need to keep persistent data such as user profiles, user data, and golden VM images synced between the two sites by using a replication mechanism, such as DFS-R in a hub-spoke topology or another third-party file share technology. If you also use App Volumes and Dynamic Environment Manager, App Volumes packages and file share data will also need to be replicated from the production site to the recovery site, as discussed later in this document, in the section Data Replication.
Full-Clone Desktops
The disaster recovery workflow recommended in the previous section works well for nonpersistent clones. There are some additional considerations for protection of persistent full-clone desktops.
First, consider: Do your users require mirror-image desktops after a production site failure? If the answer is yes, you will need to replicate your production full-clone desktops periodically to the recovery site. This is the most expensive type of protection. For every production full-clone desktop, you will need an equivalent recovery full-clone desktop in a recovery location, always running. You will also need to script the import of recovery full-clone desktops into the Horizon pod in the recovery site as a manual full-clone pool.
Most customers find that, given the cost of providing a fully mirrored desktop, it is acceptable to give their persistent full-clone desktop users a recovery desktop that offers a similar service by using one of the following strategies:
- Create a new full-clone desktop in the recovery site using the same golden image as was used in production.
- Create instant-clone desktops that can offer a good-enough service in the event of a disaster.
In these scenarios, because you are not replicating the full-clone desktops, any user customization or data not saved in a file share and replicated to the recovery site will be lost, so you will need to ensure that all important user data resides on a file share.
Deployment Options
Horizon can be deployed on any supported hypervisor environment or Cloud certified partner platforms. Horizon resources can also be provisioned using Horizon Cloud Service. To provide business continuity and an alternate location to run Horizon workloads, you can either use the same deployment option that you already employ or use one of the other deployment options.
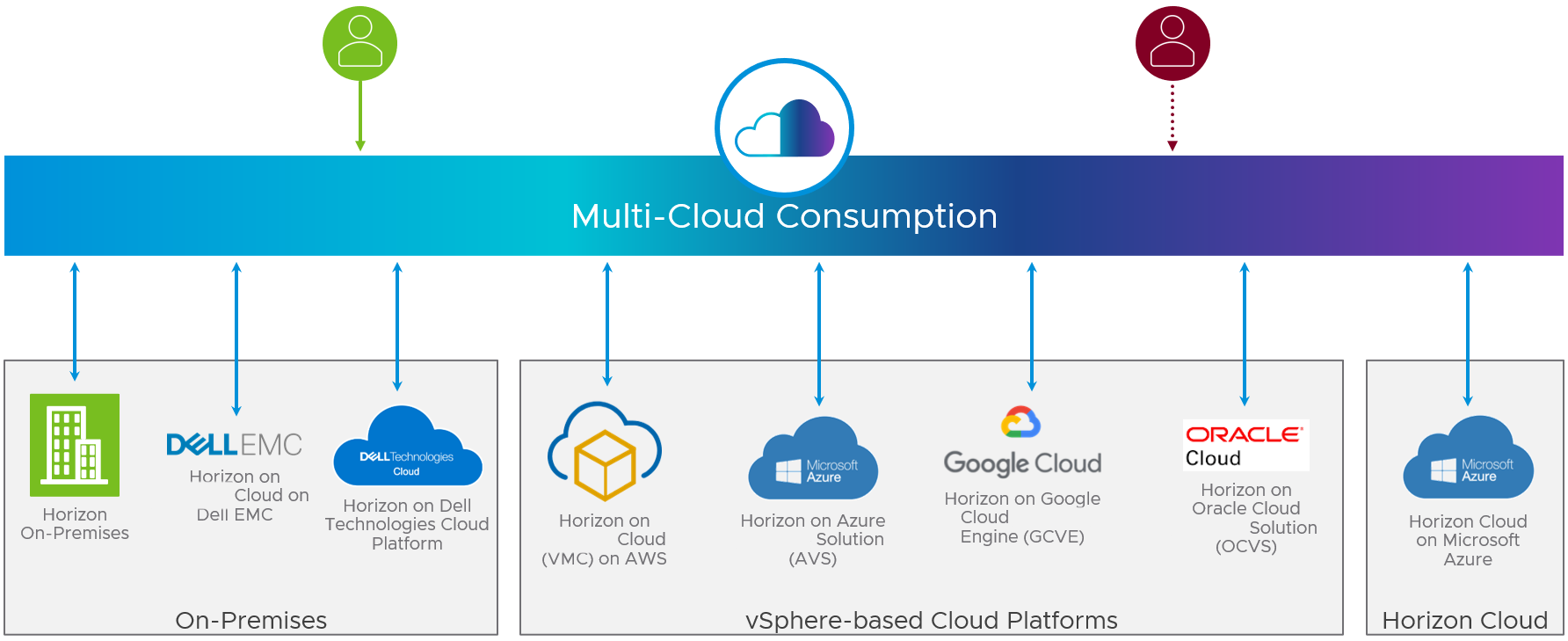
Figure 5: Multi-Cloud Deployment Options for Horizon
If you use the same deployment option for both your production site and your alternative site, place the additional site in a different location or different cloud region to ensure separation. Each deployment option should be designed, deployed, and managed separately.
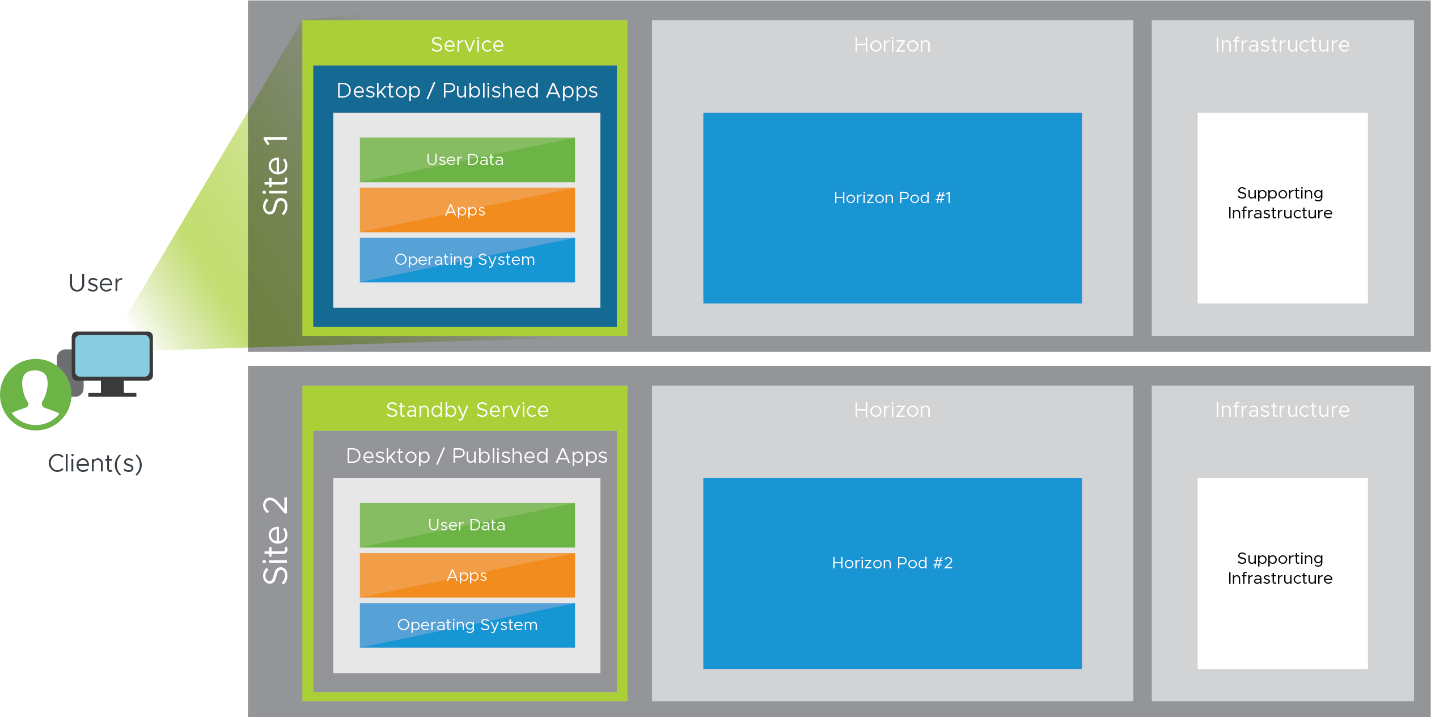
Figure 6: Horizon Infrastructure in Two Sites for Disaster Recovery
If you choose a vSphere-based Horizon deployment, once you have completed the deployment, you have the option of connecting it to the Horizon Control Plane using the Horizon Cloud Connector. Doing so gives you the ability to manage your hybrid environment from the Horizon Universal Console user interface. If you choose Horizon Cloud on Microsoft Azure, the deployment is connected to the Horizon Control Plane, and you do not need the Horizon Cloud Connector. For more information, see Getting Started with Horizon Service.
To ease user experience and consumption during an outage event, you can deploy Universal Broker, Workspace ONE Access, or both with Horizon.
This document applies broadly to providing disaster recovery with one or more deployment options for Horizon, where sites are placed in two different locations.
Horizon 8 Deployed in a Private Data Center
Many companies start with a private data-center deployment of Horizon, which runs on a vSphere Software-Defined Data Center (SDDC) infrastructure. When designing a DR solution, one deployment option for the recovery site is to create another on-premises Horizon environment in a different location.
For more information about this multi-site approach, see the Horizon 8 Architecture chapter in the Workspace ONE and Horizon Reference Architecture.
Horizon Cloud on Microsoft Azure
Horizon Cloud on Microsoft Azure is a Horizon platform running on Microsoft Azure that leverages a different set of building blocks than Horizon on vSphere to achieve the same goal of delivering virtual desktops and applications. Deploying a Horizon Cloud pod on a Microsoft Azure infrastructure is straightforward. If your organization does not already have access to Azure resources, Microsoft provides you details on how to acquire Azure capacity on their Azure portal.
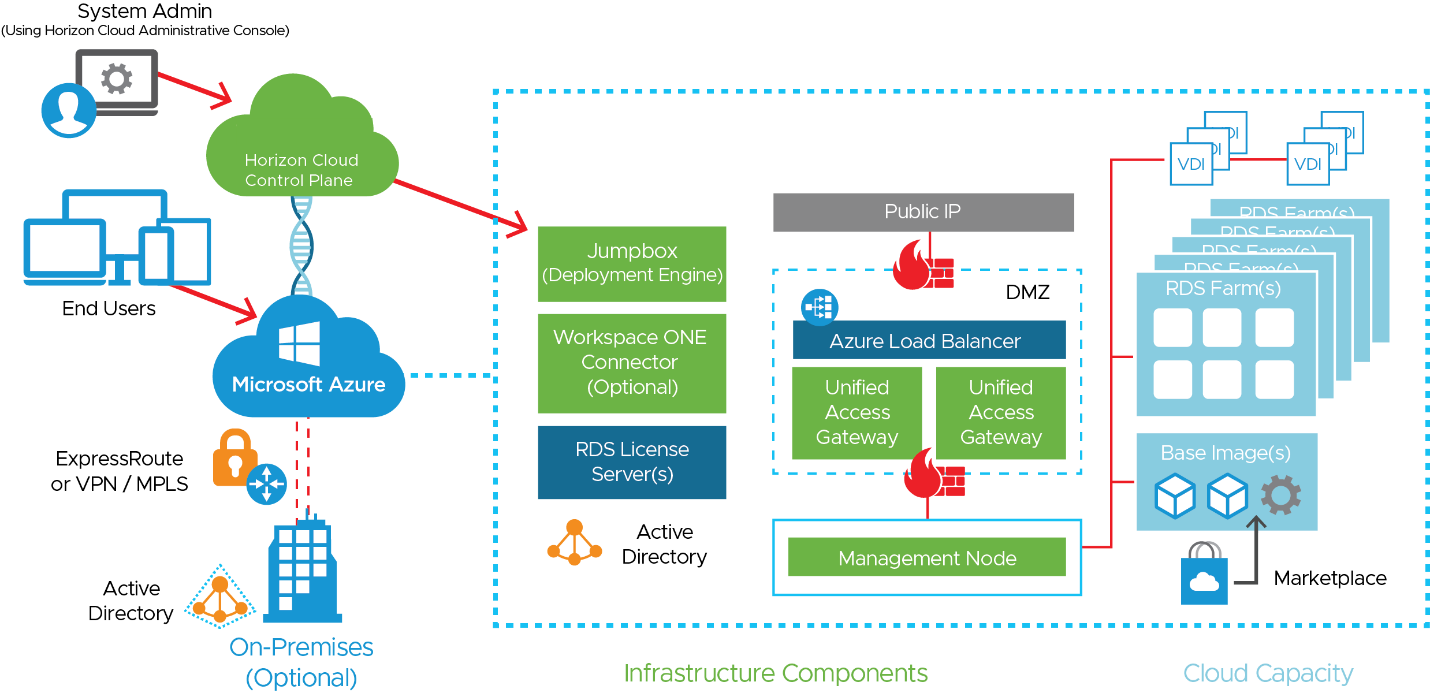
Figure 7: Horizon Cloud Service on Microsoft Azure Logical Architecture
For more information, see the Horizon Cloud on Microsoft Azure - first-gen Architecture chapter of the Workspace ONE and Horizon Reference Architecture. It is important to understand the components that are deployed, how Horizon Cloud on Microsoft Azure scales, and how it is designed for multiple sites. Refer to these sections of the Workspace ONE and Horizon Reference Architecture:
Horizon 8 on VMware Cloud on AWS
Horizon 8 on VMware Cloud on AWS (VMC on AWS) delivers a seamlessly integrated hybrid cloud for virtual desktops and applications. It combines the enterprise capabilities of the VMware SDDC (delivered as a service on AWS) with the capabilities of Horizon 8.
With this solution, you can provision an entire SDDC, including the Horizon management components, in a matter of hours.
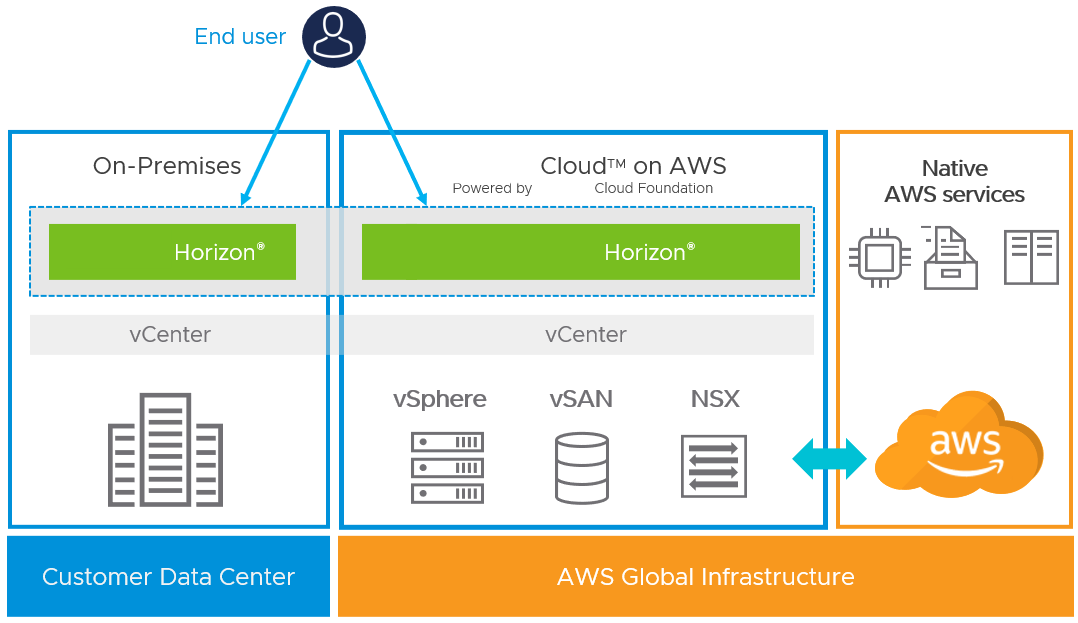
Figure 8: Horizon 8 on VMC on AWS
Horizon 8 on Azure VMware Solution
Azure VMware Solution (AVS) is a cloud platform built on the VMware Cloud Foundation, a comprehensive offering of software-defined compute (vSphere), storage (vSAN), networking (NSX), and management (vSphere and HCX) services. With this option, you deploy Horizon 8 in an AVS private cloud, which also lets you take advantage of Azure’s high availability, disaster recovery, and backup services.
This combination of customer-managed Horizon running on Microsoft-managed vSphere infrastructure gives you control over your desktop virtualization infrastructure (VDI) while removing the need to manage the underlying SDDC and hardware components. You also get access to Azure native management, security, and services as well as the global Microsoft Azure infrastructure.
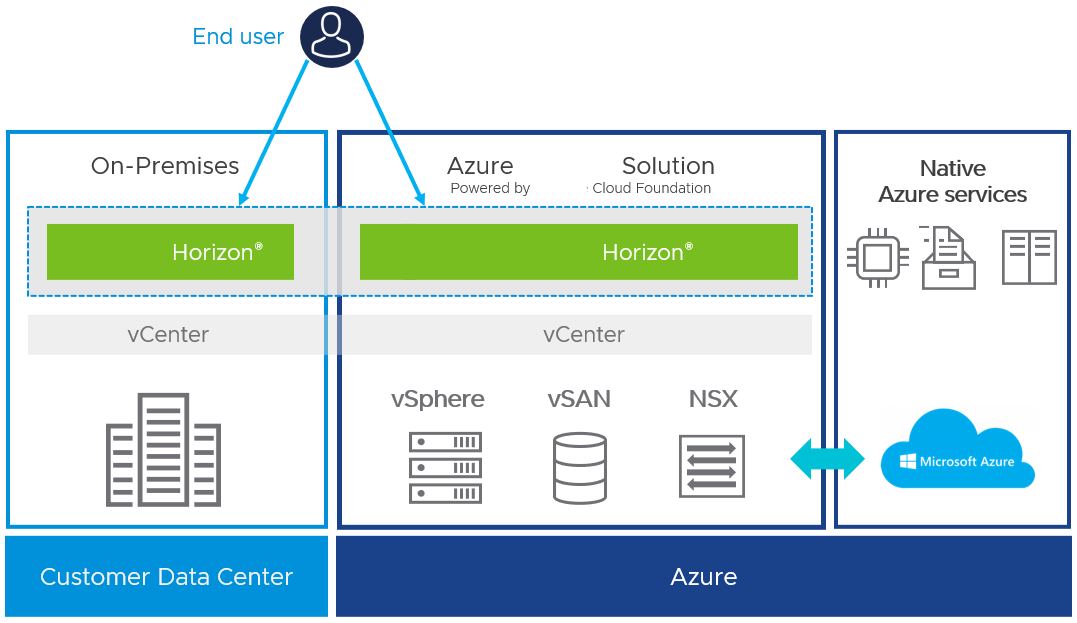
Figure 9: Horizon 8 on AVS
Horizon 8 on AVS differs from Horizon Cloud on Microsoft Azure in the following way: Horizon Cloud on Microsoft Azure is a managed Horizon solution that provides desktops and published apps as a service (DaaS) using a Microsoft Azure public cloud infrastructure. Native Azure instances, rather than a vSphere infrastructure, are used.
With Horizon 8 on AVS, because you use the same Omnissa Horizon 8 and vSphere components that you might have on-premises, you can build a scalable, elastic, hybrid platform without a complicated migration. For more information, see the Horizon 8 on Azure VMware Solution Architecture chapter in the Workspace ONE and Horizon Reference Architecture.
Horizon 8 on Google Cloud VMware Engine
Google Cloud VMware Engine (GCVE) offers a private cloud environment that can be used for Horizon deployments to address use cases such as data-center extension, disaster recovery, and burst capability. Companies that already have an on-premises Horizon 8 environment can use their existing tools, skills, and processes with Horizon 8 on GCVE.
With GCVE, a VMware Cloud Foundation stack runs on the Google Cloud Platform, meaning that an SDDC is provided as a service on Google Cloud. The software stack includes vSphere, vCenter Server, vSAN storage virtualization software, the NSX networking platform, and e HCX, an application mobility platform for cloud migration.
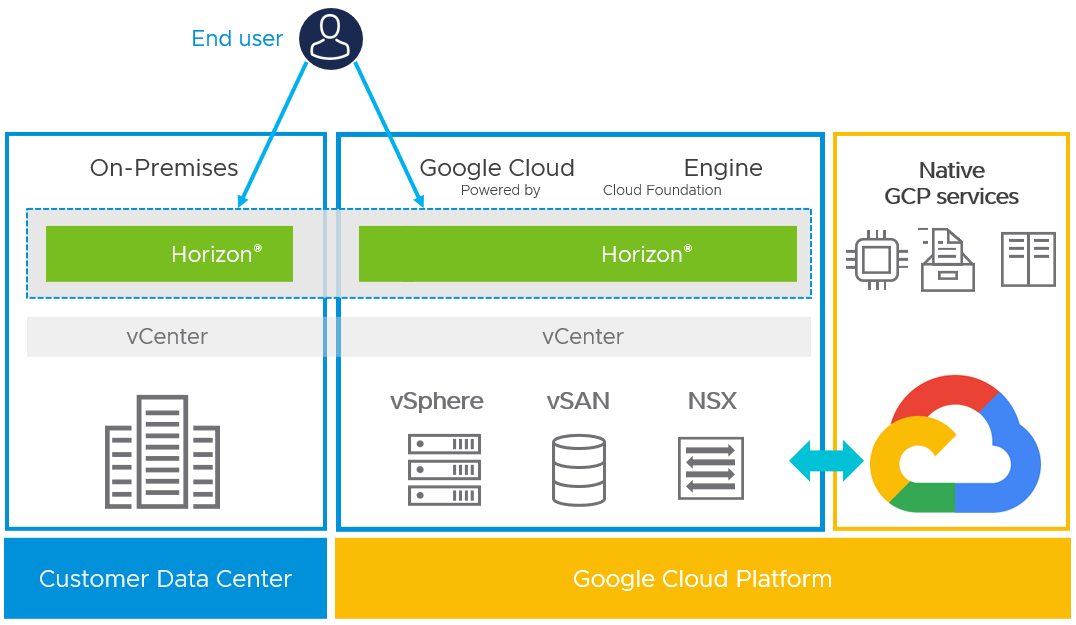
Figure 10: Horizon 8 on GCVE
The VMware SDDC runs natively on a Google Cloud bare metal infrastructure in Google Cloud locations and fully integrates with the rest of Google Cloud. Google takes care of managing the SDDC, providing full end-to-end support, including licensing, software upgrades, and patching.
For more information, see the Horizon 8 on Google Cloud VMware Engine Architecture chapter in the Workspace ONE and Horizon Reference Architecture.
Horizon 8 on Oracle Cloud VMware Solution
Oracle Cloud VMware Solution (OCVS) provides a private cloud environment that can be used for Horizon deployments to address use cases such as data-center extension, disaster recovery, and burst capability. Companies that already have an on-premises Horizon environment can use their existing tools, skills, and processes with Horizon on OCVS.
With OCVS, a VMware Cloud Foundation stack runs on the Oracle Cloud Infrastructure, meaning that an SDDC is provided as a service on Oracle Cloud. The software stack includes vSphere, vCenter Server, vSAN storage virtualization software, the NSX networking platform, and HCX, an application mobility platform for cloud migration.
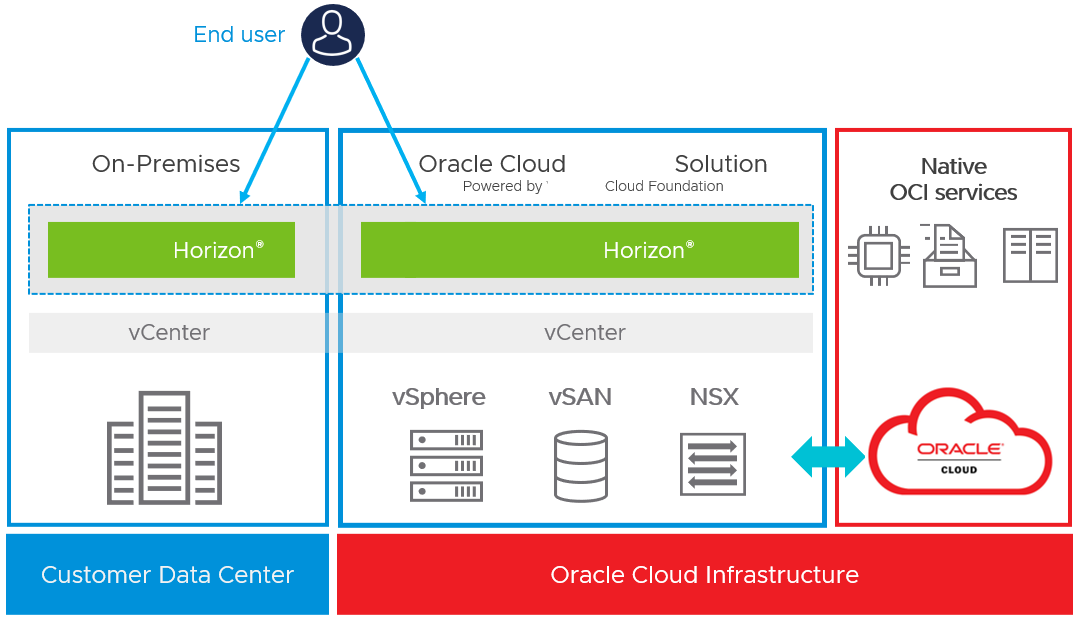
Figure 11: Horizon 8 on OCVS
How Horizon Users Leverage Multi-Cloud Resources
In the event of a disaster, users need access to the Horizon resources they use daily. These Horizon resources can be virtual desktops, published applications, or both. This section reviews the ways to present resources to users that will allow them to fail over to a recovery site in the event of a disaster.
There are several options to choose from, and in some cases a combination of them may be used. Each option has some restrictions and considerations, with some presenting a single view of the resources to the users that represents both their production and recovery resources, while some options present the two resources separately.
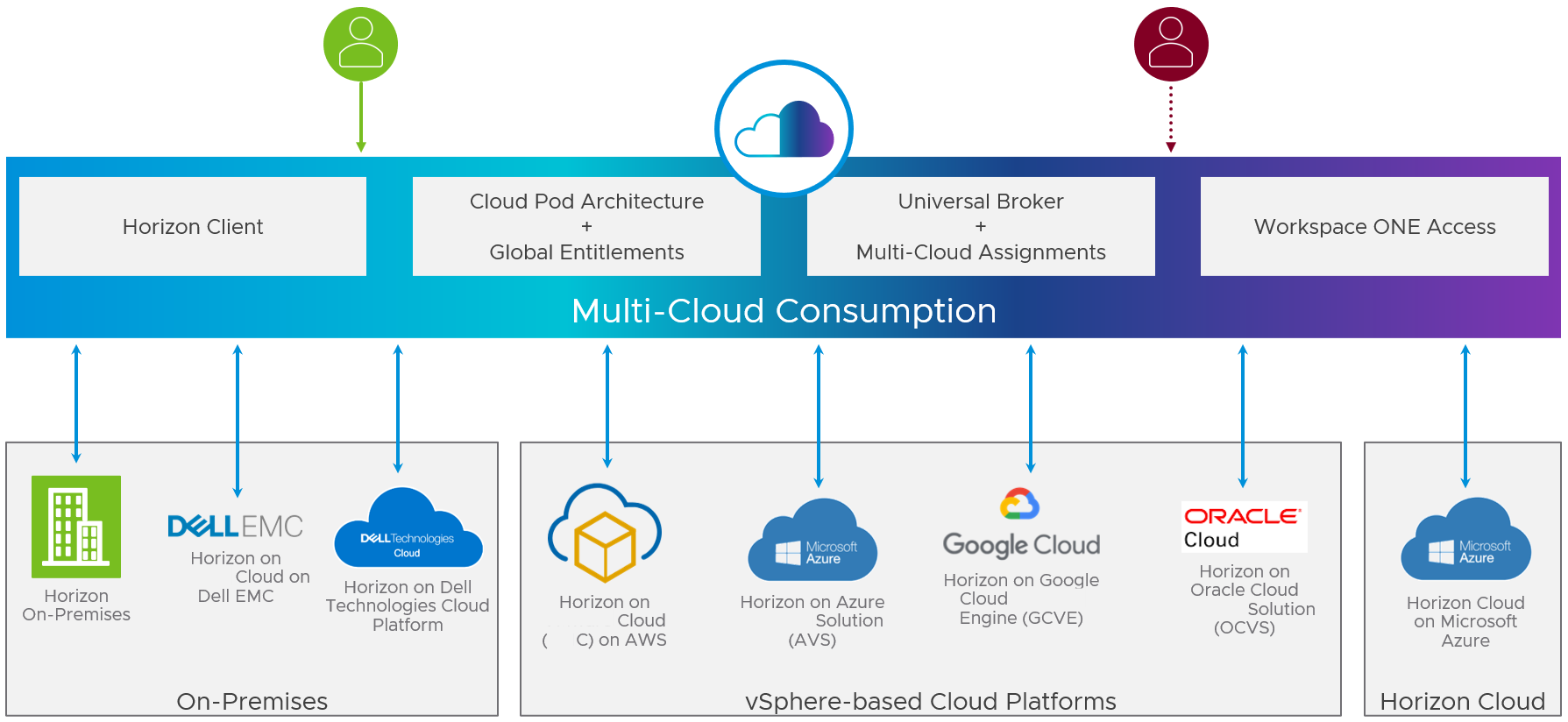
Figure 12: Multi-Cloud Consumption Options
Using Multiple Horizon Client Shortcuts
The Horizon Client software lets users access published applications and VDI desktops. One option for providing users access to two distinct Horizon environments (production and recovery) is to create two shortcuts on the Horizon Client desktop and application selector.
- One shortcut accesses the normal production Horizon environment.
- The second shortcut is to be used only in a DR event, to access the recovery Horizon environment.
- In a DR event you would inform your users to connect to the Horizon environment in the recovery site.
Additionally, you can use uniform resource identifiers (URIs) to create web page or email links that when clicked, open the Horizon Client, connect to a specific Horizon environment, or open a virtual desktop or published application.
See Horizon Client Documentation and Using URIs to Configure Horizon Windows Client for more information.
Using Multi-Cloud Assignments with Universal Broker
The Horizon Universal Broker is the cloud-based brokering technology used to manage and allocate virtual resources from multi-cloud assignments to end users. It allows users to access multi-cloud assignments in your environment by connecting to a fully qualified domain name (FQDN), which is defined in the Horizon Universal Broker configuration settings. Through the single Horizon Universal Broker FQDN, users can access assignments from any participating Horizon pod in any site.
Multi-cloud assignments are used to assign users or groups to resources. Either Horizon Cloud on Microsoft Azure or cloud-connected Horizon 8 (or Horizon 7) resources can be managed with multi-cloud assignments. In the case of a DR solution, pools at both the production site and the recovery site can be selected as a target of an assignment.
The production site is assigned as the home site for users. If the production site is available, users will be presented resources in the production site. If the production site goes down, users will automatically be routed to the DR site to access their resources. For more information, see Horizon Cloud Pods in Microsoft Azure - Creating and Viewing VDI Multi-Cloud Assignments in Your First-Gen Environment.
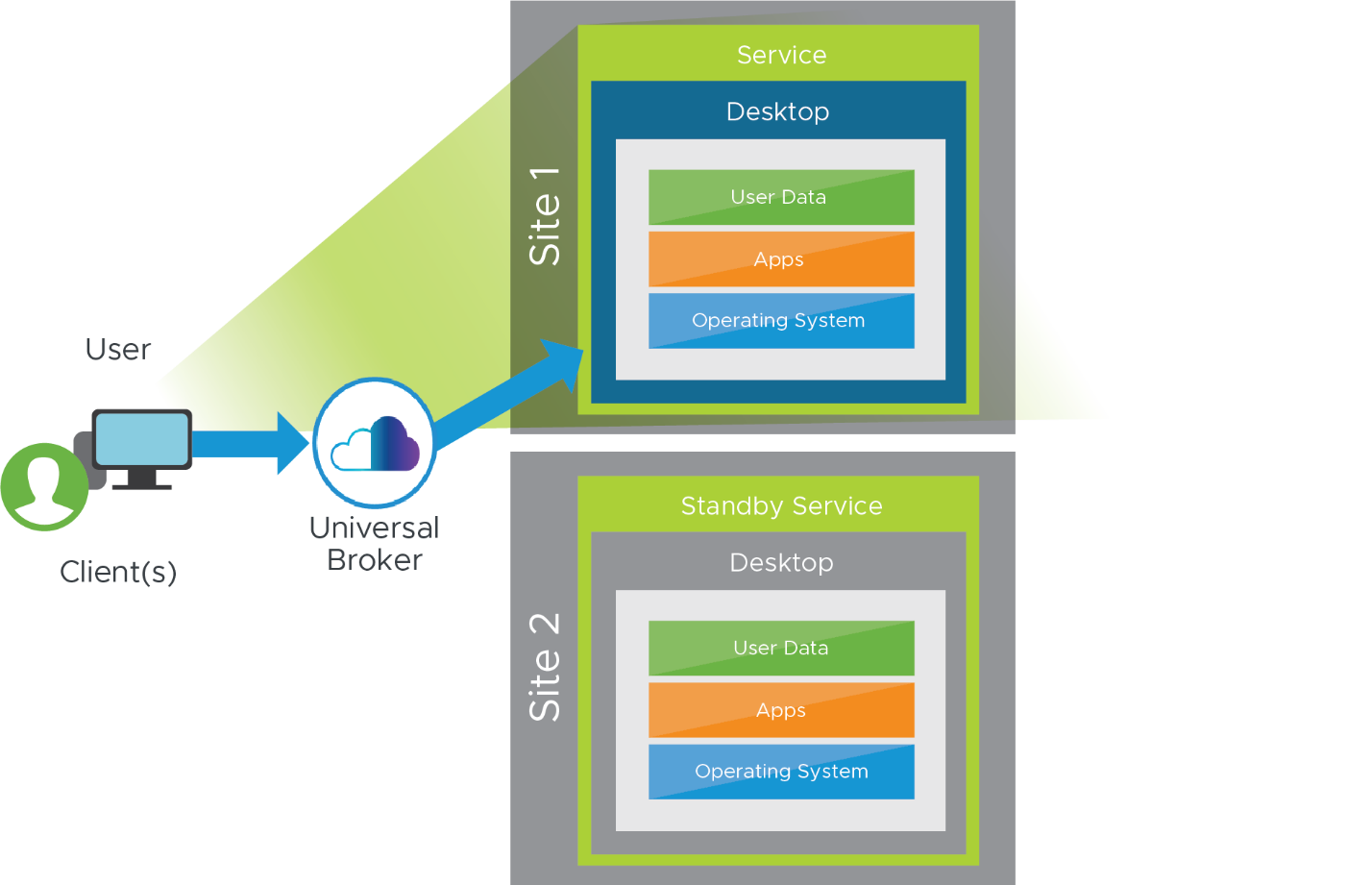
Figure 13: Multiple Desktop Entitlements Presented and Accessed Through Universal Broker
Universal Broker and multi-cloud assignments work together to give end users the perception of using a single resource while hiding the complexity around where those resources are sourced from. Universal Broker and multi-cloud assignments do not work in the same way for all platforms and capacity types. Refer to Horizon Cloud Pods in Microsoft Azure - Creating and Viewing VDI Multi-Cloud Assignments in Your First-Gen Environment and Considerations for Assignments in a Universal Broker Environment When a Pod Goes Offline for details on configuration options and results of configuration items with Universal Broker and multi-cloud assignments.
To connect a Horizon pod to use the Universal Broker, you need to leverage the Horizon Cloud Connector and universal licensing. The Horizon Cloud Connector is a virtual machine that enables the Horizon Service to integrate with your Horizon pods. For more information, see First-Gen Tenants - Onboarding a Horizon Pod to First-Gen Horizon Cloud Control Plane.
- For Horizon 8, you must deploy a Horizon Cloud Connector for each Horizon pod that will use the Horizon Service and its features, which include the Universal Broker. The Horizon Cloud Connector is also required when subscription licensing is used. See the Horizon Cloud Connector section of the Horizon 8 Architecture chapter in the Workspace ONE and Horizon Reference Architecture.
- For Horizon 8, you must also install a Universal Broker plug-In on each Connection Server, as described in Horizon Pods - Install the Universal Broker Plugin on the Connection Server.
- With Horizon Cloud on Microsoft Azure, the Universal Broker components are already present and configured on each pod manager. You do not need to install the Horizon Cloud Connector to use Universal Broker features.
- With Horizon 8, when creating a pool, you must select the Desktop Pools Settings option of a Cloud Managed pool in order to use a pool with multi-cloud assignments.
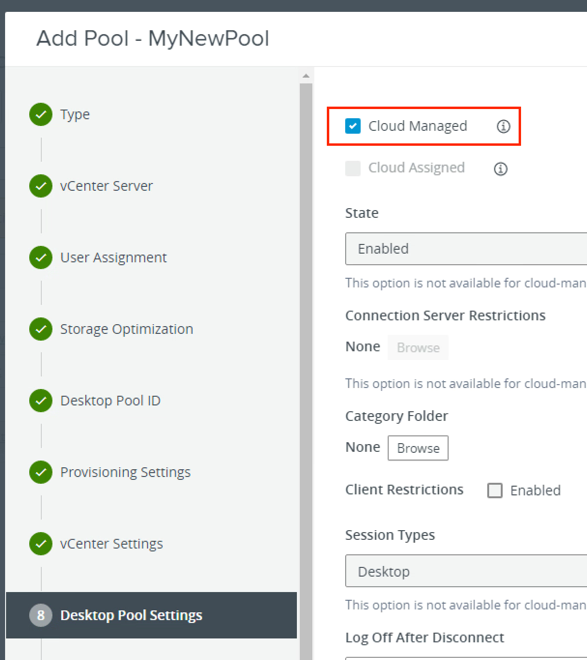
Figure 14: Select Cloud-Managed in the Horizon Pool Wizard
See Introduction to Horizon Service Universal Broker for the latest on limitations when using the Universal Broker.
For a list of the prerequisites for using Universal Broker, see System Requirements for Universal Broker.
Using Global Entitlements with Cloud Pod Architecture
Horizon Cloud Pod Architecture (CPA) introduces the concept of a global entitlement (GE) through joining multiple Horizon 8 pods together into a federation. CPA can be used between both on-premises deployments and cloud-based deployments.
As with Universal Broker, use of Cloud Pod Architecture is optional. Both Universal Broker and CPA allow you to entitle users to desktops and applications in multiple pods.
A global entitlement for a user or group can contain desktop pools or published applications from one or more Horizon pods either in the same location or in different locations. When used as part of a recovery strategy, a global entitlement could contain Horizon resources from both the production environment and the recovery environment. Because the user sees a single entitlement in the Horizon Client, the user has a straightforward means of accessing their recovery Horizon desktops or published applications when needed.
The following figure shows a logical overview of a basic two-site CPA implementation.
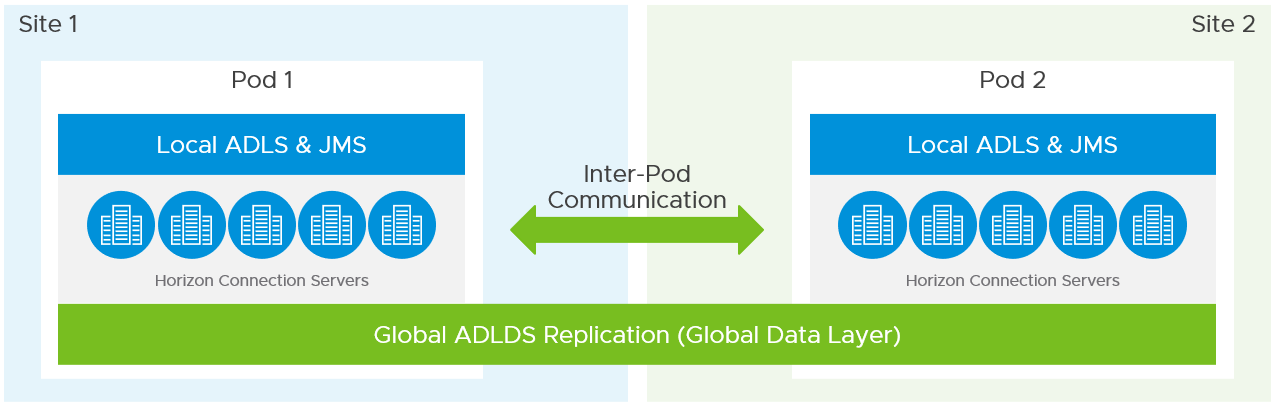
Figure 15: Cloud Pod Architecture
Additional policy controls, such as home site, home site override, and site scope can be used to control the behavior and placement of a session for the user.
The scope policy determines the scope of the search when Horizon looks for desktops or applications to satisfy a request from the global entitlement. The scope can configure Horizon to search only on the pod to which the user is connected, only on pods within the same site as the user's pod, or across all pods in the pod federation.
One consideration to be aware of is potential hair-pinning of the Horizon protocol traffic through another Horizon pod than the one the user is consuming a Horizon resource from. This can occur if the user’s session is initially sent to the wrong Horizon pod for authentication. This flow is illustrated in the following figure.
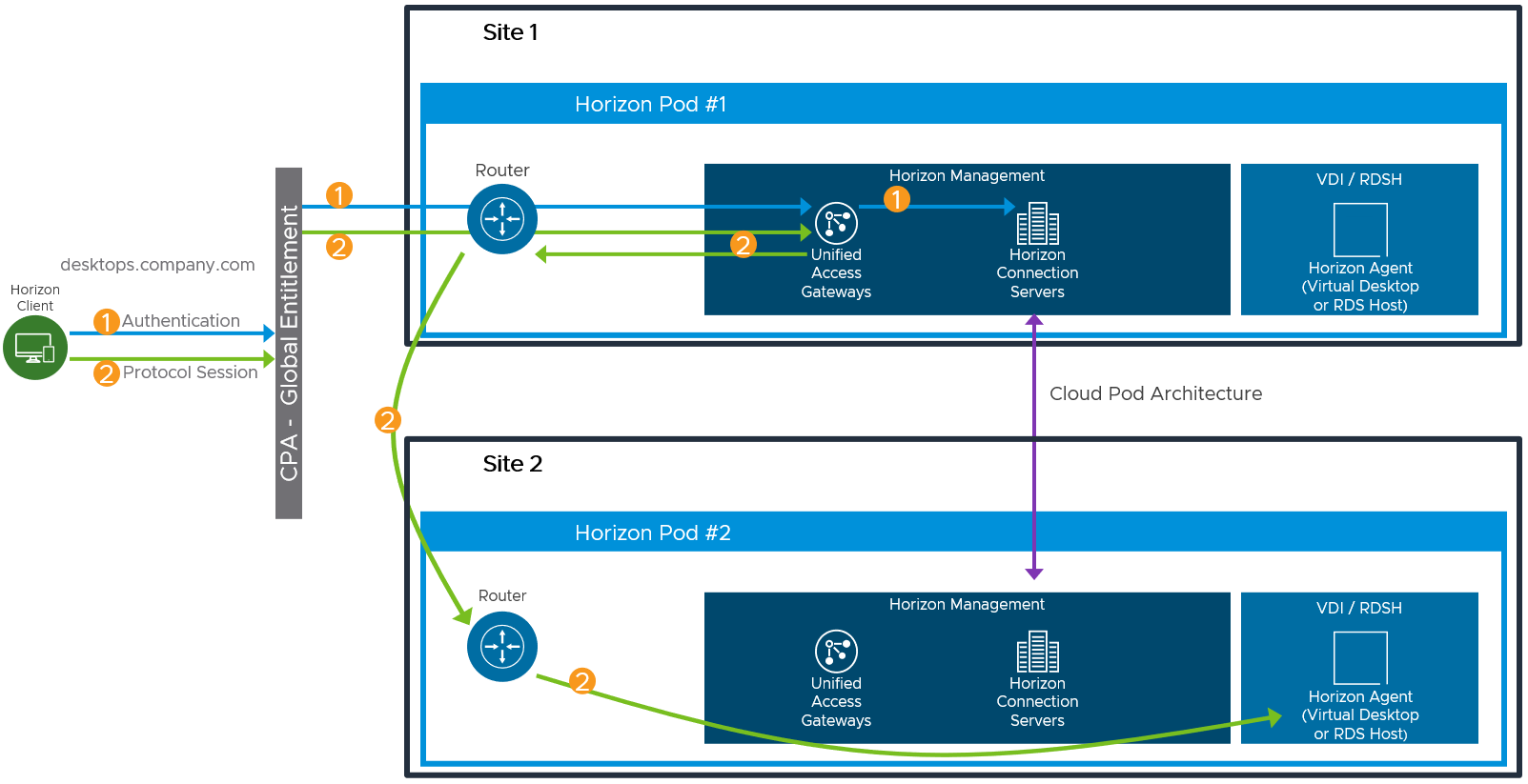
Figure 16: Horizon Protocol Traffic Hair-Pinning Through Another Horizon 8 Pod with CPA
Note: Instead of using CPA, you can use multi-cloud assignments with Universal Broker, as discussed in the previous section, to avoid this potential for protocol traffic hair-pinning.
Using the Workspace ONE Access Catalog
Omnissa Workspace ONE Access provides single sign-on and conditional access to a self-service catalog of Horizon virtual desktops and published applications, in addition to any SaaS, web, cloud, and native mobile applications you might want to configure. The following screenshot shows an example of the self-service catalog displaying shortcuts for launching a production desktop and a DR desktop.
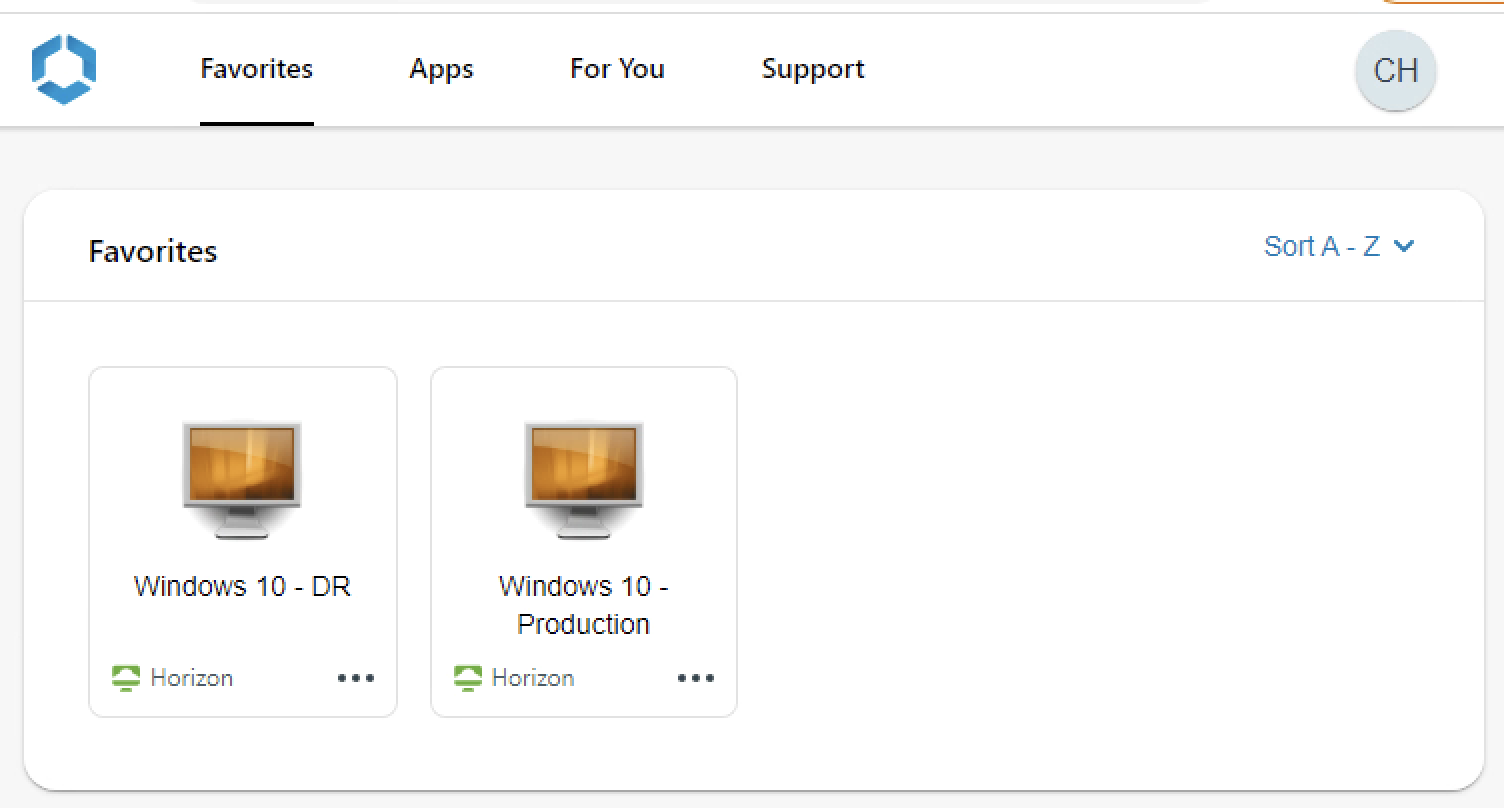
Figure 17: Workspace ONE Access Catalog Opened in a Browser
Workspace ONE Access can be integrated with Horizon 8 and Horizon Cloud Service – next-gen. This allows Horizon entitlements to be synchronized to Workspace ONE Access so that when a user logs in, they see the Horizon desktops and applications that they are entitled to. For details on the integration of Workspace ONE Access and Horizon, see High-Level Horizon-Workspace ONE Access Integration Design.
One option for providing users access to their DR resources is to integrate both the production and the recovery Horizon environments into Workspace ONE Access. Users can be assigned resources at both the production and the recovery sites. Users see both Horizon entitlements when they authenticate to Workspace ONE Access. To simplify desktop selection for end users, the pools can be named something like “Windows 10 – Production” and “Windows 10 – DR,” as shown in the figure above.
Alternatively, Workspace ONE Access can also be used in conjunction with multi-cloud assignments using Universal Broker or with global entitlements as part of Cloud Pod Architecture. When these are used with Workspace ONE Access, the user only sees a single shortcut for the resource in the self-service catalog.
Data Replication
Designing your disaster-recovery service involves choosing how to make various components available in both the production and the recovery environments. These components include user data, applications, and golden VM images. It might seem that all you need are the golden images used to recreate desktops, but without applications and the user’s data, you do not have a full-service offering.
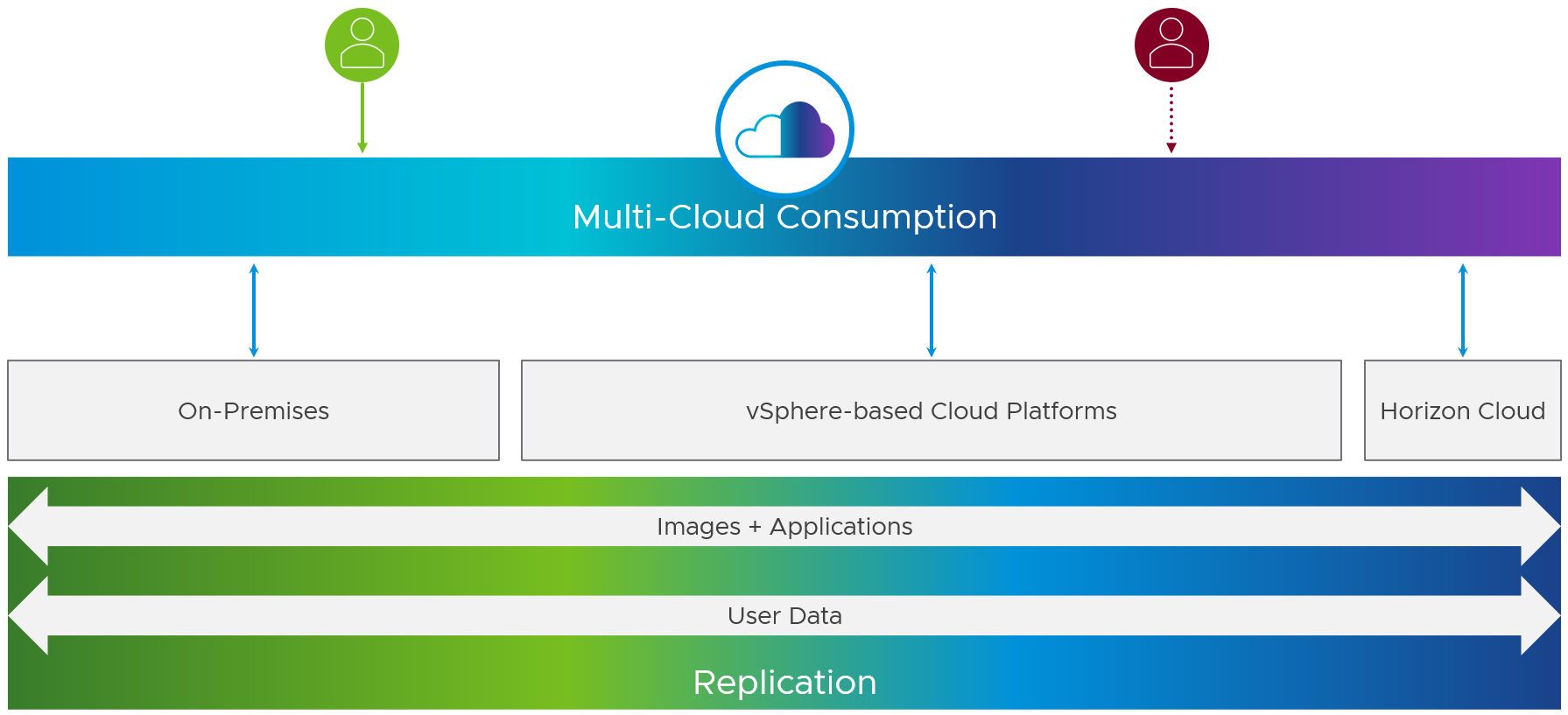
Figure 18: Data Replication Between Horizon Environments
For each of these components, you need to decide whether your DR strategy will include that component and, if so, which method to use for replicating it across environments or reproducing it in the recovery environment. Determine what data is considered important enough to replicate to your DR location, and how often that replication takes place. You can also look at a phased approach to recovery of data, where the most important data is replicated frequently and made available quickly in a DR event, but less important data is replicated less frequently and might become available only after a longer period.
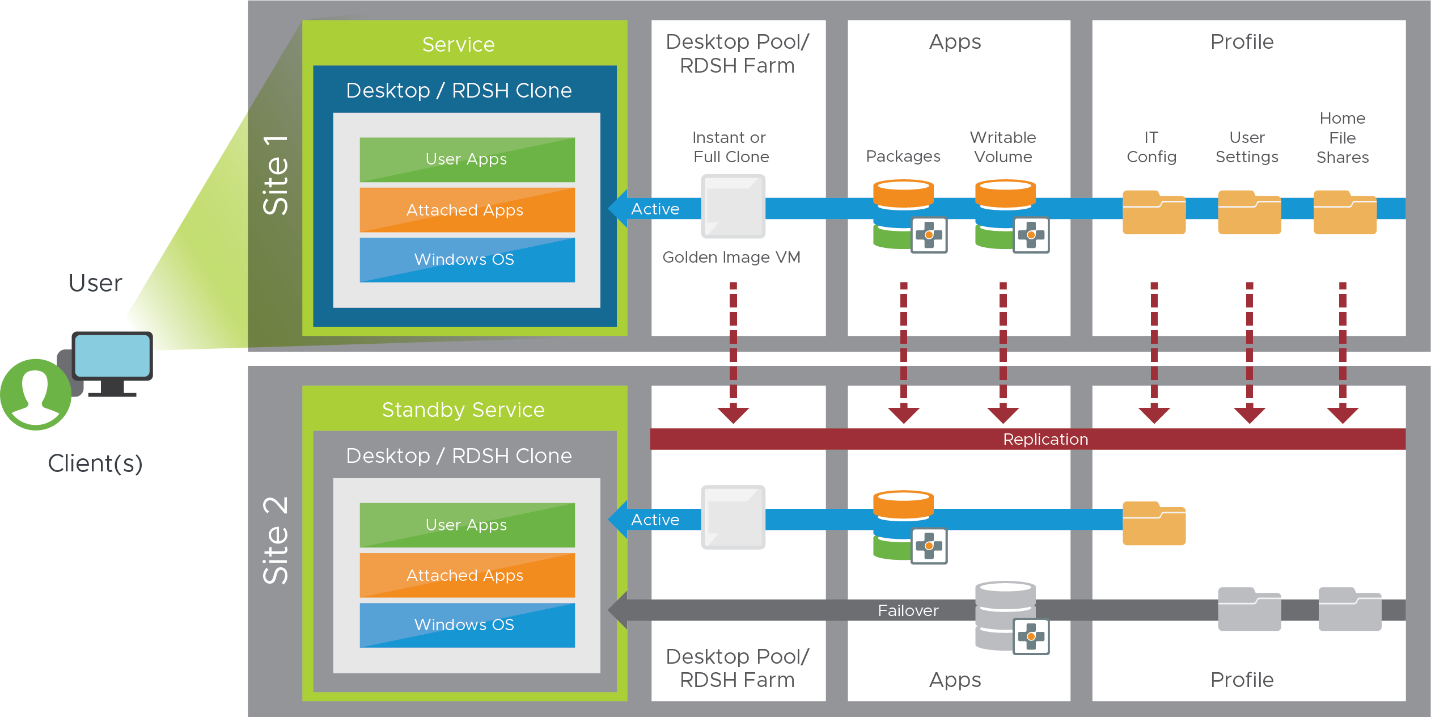
Figure 19: Data Replication Considerations
Replicating the Golden VM Image
A golden VM image is the base VM from which pools of VDI desktops or farms of RDSH servers are created. You will want to use the same VM image in all locations whenever possible because without a golden image, no pools or farms can be created.
There are various methods that you can use to replicate the golden VM between your production and recovery environments.
Note: The data format (VHD) that Horizon Cloud on Microsoft Azure uses for VMs is incompatible with that used by vSphere (VMDK). Therefore, VM images are not directly interchangeable between Microsoft Azure and vSphere-based platforms.
For more information on how to create a golden VM image, see Manually Creating Optimized Windows Images for Horizon VMs.
Automating VM Replication with the Image Management Service
The Image Management Service is a component of the Horizon Control Plane, included with the Horizon Service. The cloud-based Image Management Service simplifies and automates the management of system images used by desktop assignments, such as desktop pools and server farms, across your cloud-connected Horizon pods.
The Horizon Image Management Service has the following features and benefits:
- Centralized catalog of images managed across all cloud-connected Horizon pods.
- Automated replication of images across cloud-connected Horizon pods.
- Automated version control and tracking of images.
- Automated updates to desktop assignments with customized images by using desktop markers. With desktop markers, you can easily update desktop pools and server farms with newer golden images or roll back to older versions of images, as necessary.
The Image Management Service is currently only supported for use with Horizon deployed on-premises and with Horizon Cloud on Microsoft Azure. Availability and support for other cloud platforms is planned.
For more details on what the Image Management Service is and how it works, see the Horizon Image Management Service section of the First-Gen Horizon Control Plane Architecture chapter of the Workspace ONE and Horizon Reference Architecture, and see the Image Management Service section of the Horizon Control Plane Services focus page.
Sharing Content Libraries Across vCenter Instances
vSphere content libraries are container objects for VM and vApp templates and other types of files, such as ISO images and text files. You can use the templates in the library to deploy VMs and vApps in the vSphere inventory. You can also use content libraries to share content across vCenter Server instances in the same or different locations.
You can create a local content library to store and manage content in a single vCenter Server instance. If you want to share the contents of that library, you can enable publishing. When you enable publishing, other instances can use a subscribed content library that points to the library. Its content can be used if HTTP(S) traffic is allowed between the two systems.
Using a content library is ideal when you are leveraging one or more platforms that do not allow attaching extra datastores, such as GCVE, AVS, and VMC on AWS.
For more details on content libraries, see Using Content Libraries in the vSphere documentation.
Storing Golden Images in Shared Datastores
To store golden VM images on platforms that allow attaching datastores, such as on-premises vSphere, you can use network-based storage, such as an NFS or iSCSI datastore, attached to every host.
For more details on using a shared datastore, see Mount Datastores in the vSphere documentation.
Manually Exporting and Importing OVF Template Files
If using a content library or shared datastore is not desired or possible, you can export the golden VM to an OVF (Open Virtual Format) template file and import the OVF file on other instances.
For more details on using OVF, see Export an OVF Template and Deploy an OVF or OVA Template in the vSphere documentation.
You can also use PowerCLI to export a VM to an OVA file.
Get-VM -Name <VM-Name> | Export-VApp -Destination <Export-Directory> -Format Ova -Force
Get-VM -Name Win10-20H2 | Export-VApp -Destination I:\Images Format Ova -Force
Replicating Applications
Applications, which can be delivered either in the virtual desktop or as published applications by RDSH servers, need to be replicated, or reproduced, and available in the recovery site.
The methods you choose will affect the way you design and deliver your DR service. If Omnissa App Volumes is used with your Horizon implementation, you must consider which features are supported on your chosen infrastructure platform before proceeding with your DR planning.
Applications in the Golden Image
Applications can be installed directly in your golden images. Consider the following benefits and limitations.
Table 2: Considerations for Applications in the Golden Image
| Benefits |
|
| Limitations |
|
With applications installed in your golden image, DR planning should focus on making the golden image available for use at the recovery site. Earlier in this document, the Replicating the Golden VM Image section discussed the different methods of replicating golden images containing applications.
Applications Delivered Using App Volumes Packages
App Volumes abstracts applications from the golden image and dynamically delivers them to users and VMs as needed. Adding App Volumes to your Horizon implementation allows you to separate application lifecycle management from OS lifecycle management, resulting in several operational efficiencies. With the increasing supportability of App Volumes across infrastructure platforms, you might choose to include App Volumes in your DR plan. Consider the following benefits and limitations.
Table 3: Considerations for Applications in App Volumes Packages
| Benefits |
|
| Limitations |
|
Applications are abstracted from the golden image and packaged in application packages. Your DR strategy should include duplication of App Volumes infrastructure at the recovery site, along with any required application packages.
Note: App Volumes is integrated and included as a service with Horizon Cloud Service – next-gen. When using Horizon Cloud Service – next-gen with cloud-native capacity, such as Microsoft Azure, as your target DR platform, no additional App Volumes infrastructure is required.
You can either replicate existing App Volumes packages or recreate them, depending on the type of source and destination environments. Recreating packages follows the same process used when the original packages were created and works regardless of the types of Horizon deployments being used.
Automatic replication of existing App Volumes packages is currently only supported between on-premises vSphere-based environments. To build and replicate application packages between two vSphere sites, see Multi-Site Design in the App Volumes Architecture chapter of the Workspace ONE and Horizon Reference Architecture. The section describing the use of storage groups to replicate application packages between App Volumes instances with a non-attachable datastore is currently applicable when your production and recovery infrastructure platforms are both on-premises vSphere.
Applications Captured in App Volumes User-Writable Volumes
In a nonpersistent virtual desktop environment, all applications that the user installs are removed after the user logs out of the desktop. Writable volumes configured with a user-installed app (UIA) template store the applications and settings of users and make the writable volume persistent and portable across nonpersistent virtual desktops.
Note: App Volumes user-writable volumes are not supported with Horizon Cloud on Microsoft Azure.
Table 4: Considerations for Applications Delivered Using Writable Volumes
| Benefit | Supports use cases such as providing development and test machines for users to install custom applications on nonpersistent virtual desktops. |
| Limitation | Replicating writable volumes between sites adds complexity to your DR strategy. |
When creating a DR design, you must decide whether replicating writable volumes from the production site to a DR site is necessary. This decision will guide your DR strategy. In the context of replication, there is a key difference between App Volumes packages and App Volumes writable volumes.
- Packages are read-only to users and therefore can be safely replicated. All copies can actively be used.
- Writable volumes can be written to by the user, so that although replication is possible, only one copy will be designated as the live copy that is actively being used.
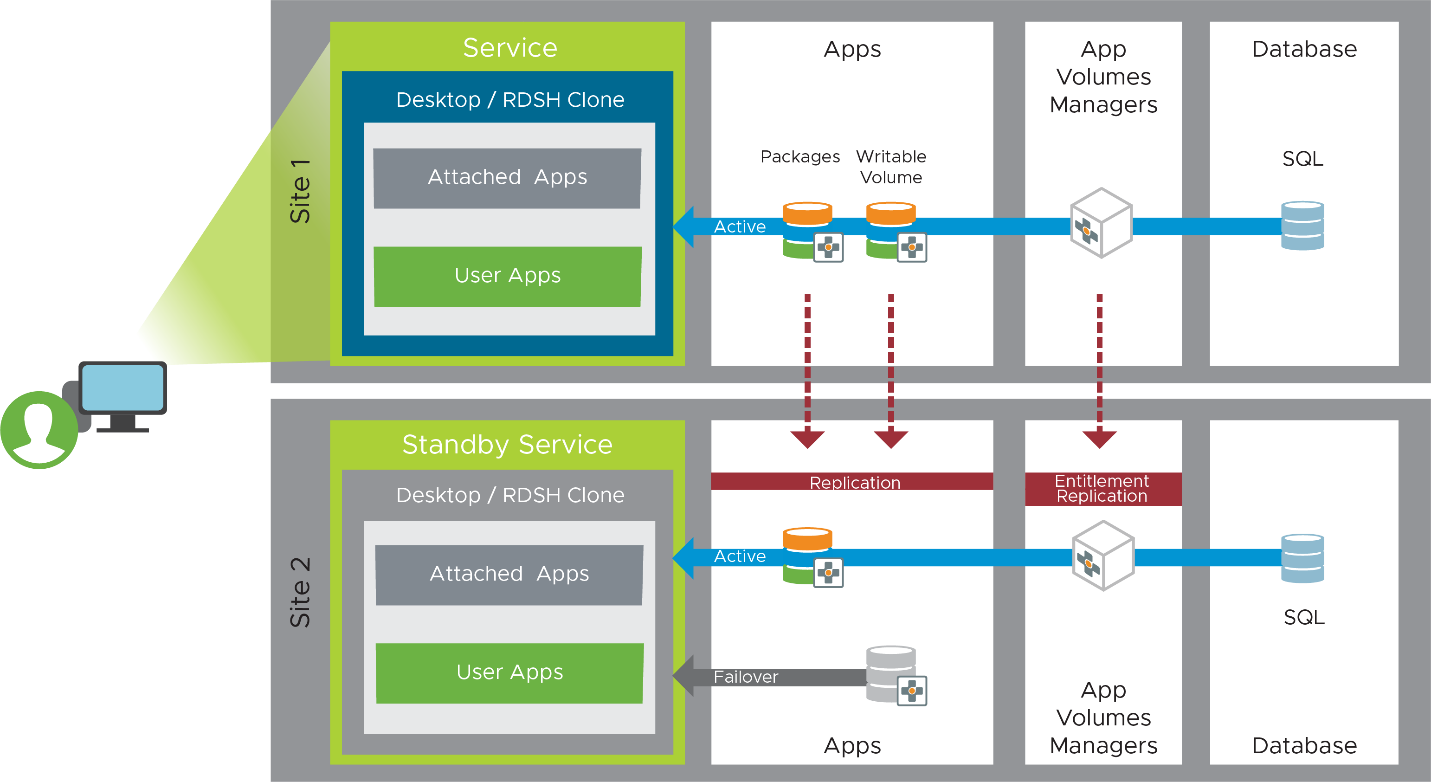
Figure 20: Replication of Applications with App Volumes
You might find that providing only those applications delivered in the golden image or in App Volumes application packages is sufficient in the case of a disaster, which negates the need to replicate the writable volumes. In this case, no action is required. If you decide not to replicate existing writable volumes, consider providing new writable volumes at the DR site. This provides end users the option to reinstall user-installed applications if absolutely required. In this case, create and assign new writable volumes in the App Volumes instance at the recovery site.
Replicating writable volumes requires careful planning because users can write to writable volumes. You can back up and restore writable volumes and essentially copy them from one site to the other, but you do not want the user to access the copy until a DR event. If you allow the user access to both copies of their writable volume, the writable volumes might become out of sync. From the user’s perspective, only one site and one copy of their writable volume should be active. The copy at the recovery site is a standby and should be made active only in the case of a DR event.
Of course, this also raises questions about RPO and RTO. How often should you copy the writable volumes from site 1 to site 2? How long would it take to make the copy in site 2 active for the user? Some organizations decide not to protect the writable volumes because of the data replication challenges and cost. For them, in a DR event, presenting the desktop with the App Volumes packages and Dynamic Environment Manager data suffices.
You could also consider only backing up the writable volumes very infrequently or not initially giving users their writable volumes in a DR event but instead focusing on the core components and then adding nice-to-have things like writable volumes later.
Replicating Profile Data
Windows profile data includes user content data and user configuration data. You may choose to manage profile data with one or multiple tools. For additional information about Windows profile components, see Anatomy of a User Profile. The following sections provide an overview of commonly used tools to manage profile data and the options for replicating data between the production and recovery sites.
Many technologies are available to aid in the replication of data. Due to the nature of profile and user data, most replication should be regarded as active-passive, where one copy will be live while the other is passive, standing by to be used in a DR event. You will need to consider how to promote the passive copy in a DR event. Because the DR copy becomes the live copy during a DR event, and users will make changes to that copy, you will also need to understand how to reverse replication when the production site becomes available and how to fail back when the DR event is resolved.
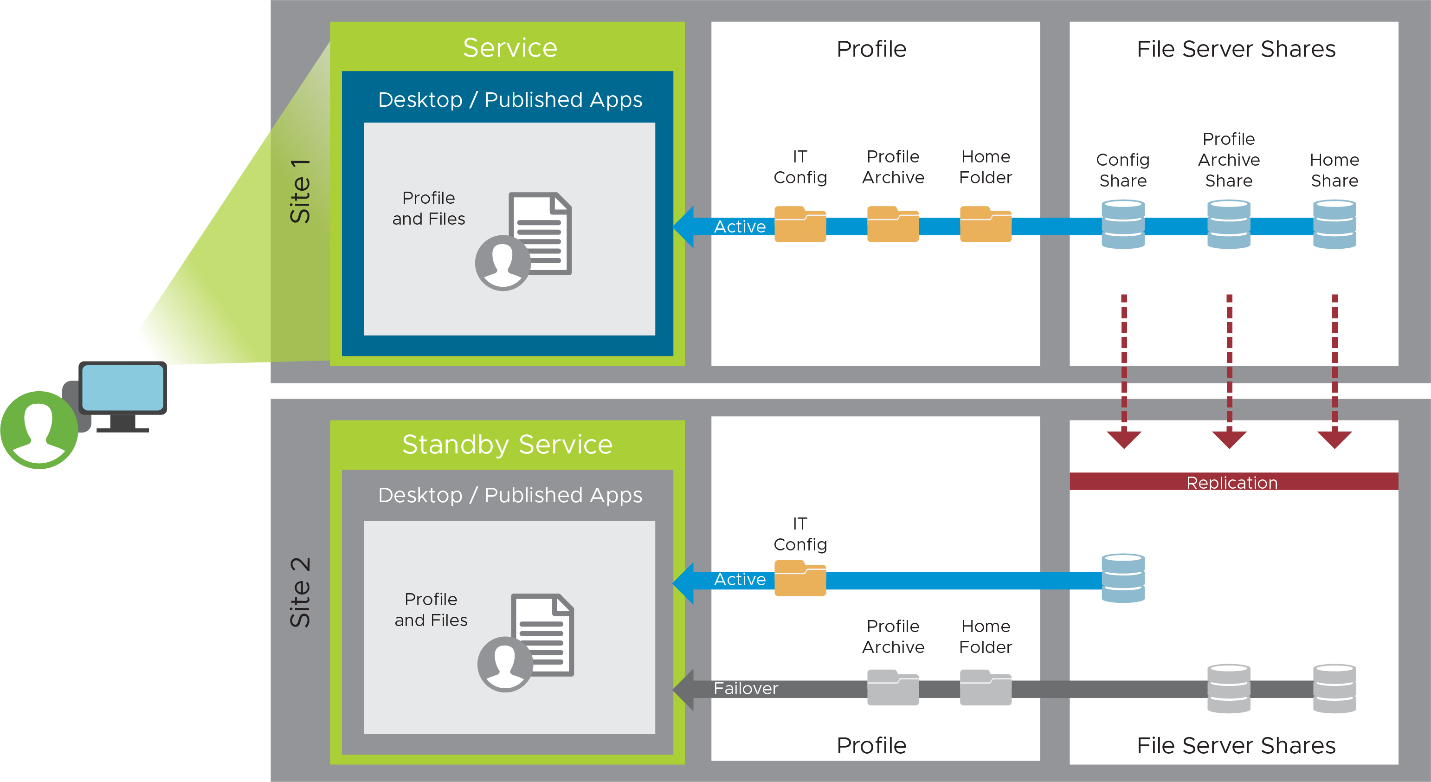
Figure 21: Replication of User and Profile Data
Replicating Dynamic Environment Manager File Shares
Dynamic Environment Manager provides profile management by capturing user settings for the operating system and applications. User content data is managed through folder redirection, which can be configured either by using Dynamic Environment Manager or by using Windows policy objects. When designing your DR service, you may choose to restore user configuration data, user content data, or both.
Unlike traditional application profile management solutions, Dynamic Environment Manager does not manage the entire profile. Instead, it captures user configuration data for applications and Windows settings that the administrator specifies. This reduces login and logout time because less data needs to be loaded. Alternatively, for specific applications, the settings can be dynamically applied when a user launches the application, rather than at login, making the login process more asynchronous.
Dynamic Environment Manager (DEM) and folder redirection require little infrastructure, making replication relatively easy. The following components should be considered in your DR strategy:
- File server infrastructure – Used to host folder redirection and Dynamic Environment Manager shares.
- Configuration share – Share on a file server containing Dynamic Environment Manager configuration rules.
- Profile archives share – Share on a file server containing user configuration data.
- FlexEngine configuration (GPO or NoAD) – XML- or ADMX-based configuration for the Dynamic Environment Manager (FlexEngine) agent.
- Dynamic Environment Manager management console – Stand-alone management console.
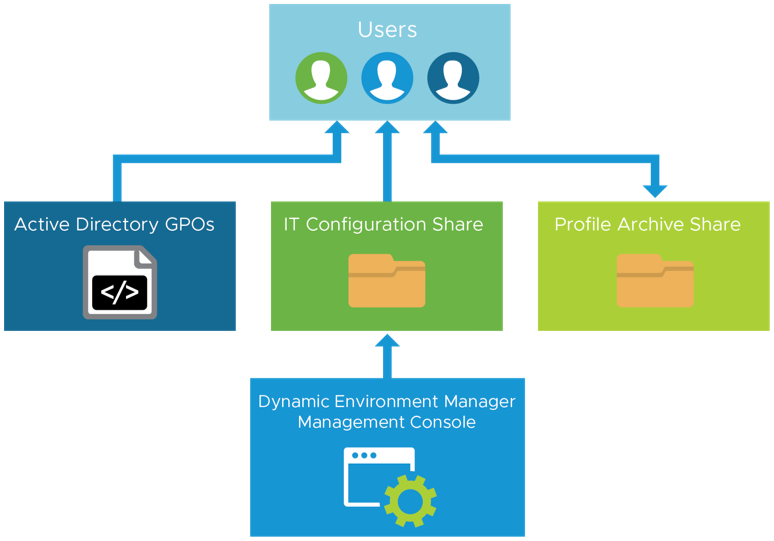
Figure 22: Dynamic Environment Manager Architecture
Replication of the Dynamic Environment Manager configuration share and profile archives share can be accomplished using various file replication technologies such as Microsoft Distributed File System Replication (DFSR).
Table 5: Considerations for Replication of Dynamic Environment Manager Shares
| Configuration Shares | Profile Archive Shares |
| Users have read access only. Only admins make changes. | Users can read and write to these shares. |
| Replication is supported. | Replication is supported. |
| All copies can actively be consumed by users. | Only one copy should be actively consumed by users. One of the replicated copies can be used in a DR event but will need to be promoted to become the active copy. |
See the Disaster Recovery and Multi-site Design sections of the Dynamic Environment Manager Architecture chapter in the Workspace ONE and Horizon Reference Architecture for more detail.
Replicating Microsoft FSLogix Containers
FSLogix provides VHD-based profile redirection technologies, which redirect part or all of a user profile to a remote file share. Profile Containers can store the entire user profile or may be combined with folder redirection to abstract user content data from VHDs to an SMB file share.
The type of data you choose to store on the Profile Containers will influence your DR strategy. Office Containers are used to store cache data for Office 365. Because this data is easily and automatically rebuilt from the cloud if the Office Container is lost, Office Containers are typically considered disposable.
For more information see:
- What is FSLogix? to learn more about Profile and Office Containers.
- ntegrating FSLogix Profile Containers with Horizon on how to use FSLogix with Horizon.
Note: FSLogix is one of many third-party solutions that work with Horizon. Although FSLogix is often integrated into Horizon designs, Omnissa assumes no responsibility to provide support for the use of FSLogix software with Omnissa products.
When designing your DR service, you must decide whether to replicate FSLogix containers to your DR site. If you are using Profile Containers with folder redirection, you may decide to replicate user content data (folder redirection) but not user configuration data (Profile Container). If you are using Office Containers for disposable cache data only, you may decide not to replicate the VHDs to the recovery site.
Consider the following when designing your DR strategy:
- FSLogix stores profile data in VHD(X) files on remote SMB shares. File- or storage-level replication technologies could be used to replicate containers to the recovery site.
- Cloud Cache may be used in your DR strategy or to create an active-active FSLogix service. See Cloud Cache to create resiliency and availability for additional information.
As with any profile data, you must consider RPO and RTO targets and the practicalities of how frequently you can replicate Profile Containers from one site to another. Sufficient bandwidth between the sites will be needed to replicate the quantity of data that changes and to accommodate the target frequency. Also consider which tasks need to be performed before replication, such as preventing users from changing data during the copy process.
Replicating App Volumes User-Writable Volumes
User-writable volumes configured with a profile template may be used to persist part or all of a user profile to a VMDK file assigned directly to an end user. User-writable volumes can store the entire user profile or may be combined with folder redirection to abstract user content data from VMDKs to an SMB file share. The type of data you choose to store in the user-writable volume will influence your DR strategy.
When designing your DR service, you will need to decide whether to replicate App Volumes user-writable volumes to your DR site. If you are using writable volumes with folder redirection, you may decide to replicate user content data (folder redirection) but not user configuration data (VMDK). The earlier section in this guide called Applications Captured in App Volumes User-Writable Volumes discussed considerations regarding replication of writable volumes.
Deprecation of Horizon Persona Management
Persona Management preserves user profiles and dynamically synchronizes them with a remote profile repository. Persona Management has been deprecated and removed from Horizon 8 (2012) and later.
View Composer persistent disks redirect the Windows profile to a local VMDK. It is also possible to use persistent disks to store Outlook OSTs, user-installed applications, or simply treat a persistent disk as a secondary hard disk for storage. Using persistent disks for anything other than profile redirection is outside the scope of this guide. View Composer and persistent disks have been deprecated and removed from Horizon 8 (2012) and later.
Persona Management and persistent disks are legacy technologies and it is recommended upgrading to modern alternatives. See Modernizing VDI for a New Horizon for guidance on selecting and migrating to a modern alternative.
Failover
In the event of an outage, business continuity policy will enact DR processes such as failover of the service and delivery of resources from your Horizon DR environment. Depending on your deployment, you might need to perform some tasks before your DR environment can accommodate your users:
- DR infrastructure – Scale up the DR infrastructure to cope with the increase in users and demand.
- Data replication – Promote copies of data in the DR location to become the active instances.
- Applications – Ensure Horizon in the DR location has access to replication or reproduced applications.
- User access – Present the DR Horizon resources to users.
Scale-Up of the Recovery Infrastructure
Depending on the normal running state of your DR Horizon environment, you might have to perform tasks to make it fully functional or to expand its capacity. For example, if you have implemented a “cold site” or “pilot-light” configuration of Horizon on a cloud-based infrastructure, you might need to add capacity by adding hosts and powering on supporting infrastructure components.
If additional capacity is required, you need to understand the process for acquiring capacity and determine the amount of time required. You should also document any additional configuration tasks that might need to be done to make use of this additional capacity.
Another consideration in scaling up the DR Horizon environment is to increase the capacity of Horizon desktop pools or RDSH server farms to handle the increase in users that will be serviced from the DR location. Ideally, any required pools or farms should already exist and be seeded with an initial size so that any provisioning tasks are minimized. Carry out tests to understand the time required to provision additional desktop clones or RDSH server clones.
Failover of Profile Data
During a failover to a recovery site, you should understand how to promote and provide access to the replicated or reproduced profile and user data.
Dynamic Environment Manager Failover
As described earlier, in Replicating Dynamic Environment Manager File Shares, there are two types of file shares.
- Configuration shares can be replicated and be actively accessible to users in the recovery site, so no intervention is required.
- Although profile archive shares can be replicated, the copy in the recovery site is a standby copy. An administrator will need to promote and enable this DR standby copy to allow users access.
To speed up recovery in a DR event, you could allow the recovery to be provided in stages, with the configuration shares available at the time of failover, and the profile archive shares becoming available shortly thereafter.
See Disaster Recovery in the Dynamic Environment Manager Architecture chapter of the Workspace ONE and Horizon Reference Architecture.
FSLogix Failover
If you have chosen to replicate FSLogix VHD(X) files to the recovery site, it is imperative to ensure end users have access to only one site at any given time to ensure profile integrity. The file share or shares containing FSLogix containers at the production site should be active. Under normal operating conditions, the file shares at the recovery site should be passive. If a disaster occurs, you will need to deactivate the production share and promote the passive share to active status.
The following example workflow applies if you are using DFS-R and DFS-N to replicate and make FSLogix containers available at both sites:
- If possible, verify that DFS-R data replication from the active folder target to the desired folder target is complete.
- Deactivate the DFS-N referral status for the active folder target.
- Enable the DFS-N referral status on the desired folder target.
Failover of Applications
This section discusses the failover of applications that are delivered in App Volumes packages or that are installed in user-writable volumes.
App Volumes Application Packages in a Multi-Instance Model
If you have built your App Volumes implementations using a multi-instance model, where App Volumes infrastructure components are duplicated at the production and DR sites, failing over in the case of a disaster is a simple process. The key to success is to ensure that the infrastructure, application packages, writable volumes, and assignments are replicated or recreated in the DR site before an outage occurs.
App Volumes application packages are utilized by end users when accessing Horizon virtual machines. Ensure application packages are available and that all necessary assignments have been created in the App Volumes Manager instance at the DR site. When you fail over to the DR site for Horizon access, users will automatically receive App Volumes application packages that have been assigned.
App Volumes User-Writable Volumes Assigned at the Recovery Site
App Volumes writable volumes are utilized by end users when accessing Horizon virtual machines. When you fail over to the DR site for Horizon access, users will automatically receive App Volumes writable volumes that have been assigned.
Presentation of Recovery Resources to Users
In a DR event, depending on how Horizon resources are presented to users, and how users are consuming multi-cloud resources, some administrative tasks might be required to direct users to their recovery resources.
Routing to a DR Site with Universal Broker and Multi-Cloud Assignments
Using Universal Broker with multi-cloud assignments in a multi-pod environment makes it easier to handle failover in a DR event. Universal Broker monitors the availability of each Horizon pod configured to use the service. When one pod is unavailable, if users are entitled to a multi-pod assignment and are not prohibited from using capacity in other Horizon pods, users will automatically be routed to available capacity on the other pod.
To set up a multi-cloud assignment in the Horizon Control Plane, see First-Gen Horizon Cloud Universal Broker and Multi-Cloud Assignments.
Important: Be careful not to set up your multi-cloud assignments with a Home Site Restriction because if you do, your users will not be automatically redirected to other pods with available capacity during a DR event.
Once the DR event is over and all capacities are back online, users will be automatically redirected to their primary capacity sites (Horizon pods), according to the rules configured in the multi-cloud assignment. Users will need to log out of all currently assigned resources to be redirected on their next login.
See Considerations for Assignments in a Universal Broker Environment When a Pod Goes Offline for more details.
Routing to a DR Site with Cloud Pod Architecture
With Cloud Pod Architecture and global entitlements, sessions are normally delivered from the users’ defined home site. In a DR event, the same global entitlement will also allow users to access resources from the recovery site when their home site is unavailable
Depending on the specific configuration of the global assignment, this failover may require administrative changes on the assignment policies:
- Modify the home site or apply a home site override to ensure that users are directed to the recovery site. See Managing Home Sites in Horizon Console.
- Ensure that the scope allows Horizon to search the recovery site and allocate desktops or published applications from the Horizon pods there. See Modify Attributes or Policies for a Global Entitlement in Horizon Console.
Accessing Recovery Resources with Workspace ONE Access
If the production and recovery Horizon environments have been integrated into Workspace ONE Access users should be directed to use the appropriate shortcut from Workspace ONE Access to access the recovery environment.
- If the production and recovery pods are separate and not using either Universal Broker or Cloud Pod Architecture, the users will have two shortcuts and will need notified to use the DR shortcut.
- If Workspace ONE Access is used in combination with Universal Broker or Cloud Pod Architecture, the users will be presented with a single unified shortcut and do not need to be notified to use a different shortcut.
Accessing Recovery Resources with Horizon Client
Where Horizon Client is being used without Universal Broker or Cloud Pod Architecture, or if Horizon is not integrated into Workspace ONE Access, the production and recovery resources must be presented separately to users.
Depending on how the Horizon shortcuts are provided to users, users should be directed to either:
- Use Horizon Client to add a new server and enter the URL administrators specify for the recovery site Horizon pod.
- Use desktop shortcuts, web page links, or links in email, as directed by administrators, to access the recovery site Horizon pod.
Other Technical Considerations
When planning for a new deployment for DR purposes, before you get started building a recovery environment, you will need to perform a health check on your existing environment and review your software versions and licenses. The following section covers the main considerations specific to Horizon and Horizon Cloud, as well as those that are common across all environments.
Health Checks
Before building a DR environment, check that your existing Horizon environment is healthy, has been properly deployed, and is sufficiently sized to cope with the number of users you must support. Check components and amend configurations, as necessary, to make sure they follow sizing, security, and other best-practice recommendations.
Review the following items and update any current environment, as necessary.
- Release versions – Review the versions of software used in the environment to make sure that the Infrastructure is running supported versions and taking advantage of all the fixes, features, and performance improvements in recent releases of Horizon. See the Version Checks section of this guide for more details.
- Sizing – The environment should be sized correctly to cope with not only current demand but also any increase that is expected during a DR event. To ensure that the current and any future environment is designed and sized correctly, review the following chapters and sections of the Workspace ONE and Horizon Reference Architecture
- Horizon 8 Scalability and Availability
- Horizon Cloud Service – next-gen Scaling and Availability
- Security – Review the Horizon communication routes used, network ports used, and firewall rules to ensure that only required traffic is allowed.
- Authentication – Review how user authentication is handled and evaluate if this should be enhanced.
- Golden VM images – Ensure that best practices have been followed for creating images to be used for virtual desktops and for Windows RDSH servers used for published applications. If the golden VM image is not properly optimized, the virtual desktop or RDSH server that is cloned from it might consume more resources than required and adversely affect user experience. Review Manually Creating Optimized Windows Images for Horizon VMs for more details.
Version Checks
The versions of software used should be reviewed to make sure that the infrastructure is running supported versions and taking advantage of all the fixes, features, and performance improvements in recent releases of Horizon. Horizon 8 is updated on a quarterly basis, and fixes, features, and performance benefits are included in the new versions.
Check the Omnissa Product Interoperability Matrix to make sure the Horizon, vSphere, and vCenter versions are supported together.
- Infrastructure – Horizon Connection Servers, Unified Access Gateway instances, vSphere and vCenter, and App Volumes Managers should be running the latest build or a recent build to benefit from the new features, enhancements, and bug fixes.
- Horizon Agent – The version of Horizon Agents used in the virtual desktops should be reviewed and updated where necessary. Ideally these should match the Horizon Connection Server version. Newer versions of agents will include both new features and performance improvements.
- Horizon Client – The Horizon Client on the users’ endpoint devices should also be updated to make sure they have the latest version. Newer versions of the client will include both new features and performance improvements. By default, the Horizon Client for Windows and Mac is configured to automatically check for updates. Android and iOS devices receive updates through the app store used for installation.
Licensing Checks
Any Horizon environment needs to be properly licensed. Horizon licensing is available in a subscription model, as either a SaaS subscription or a Term subscription. Horizon standard subscription SaaS licenses give the option for either on-premises (private data center) deployments or public-cloud deployments. Horizon universal subscriptions SaaS licenses give you the flexibility to deploy and expand on your platform or platforms of choice with a hybrid multi-cloud deployment.
Summary and Additional Resources
In a DR event, Horizon is a powerful desktop and application virtualization solution that can be accessed across multiple on-premises locations and public and private clouds. This guide outlined the various recovery site types to consider, strategies for providing access to users from multiple locations, methods for replicating user data across sites, and other technical considerations to consider. With careful planning, a Horizon DR solution can minimize the inconvenience users experience during an outage at their production site.
Glossary of Terms
Business Continuity – The capability of an organization to continue running its business at acceptable, predefined levels of function or operational capacity following a disruptive incident.
Business Continuity Plan – A predefined set of procedures that guide an organization on how to respond to an incident that disrupts business function or operational capacity.
Disaster Recovery – The process of restoring and maintaining the relevant data, equipment, applications, and other technical resources on which a business depends.
High Availability – A highly available system supports operations that continue with little or no noticeable impact to the user. A high-availability strategy should remove any single points of failure by using multiple and redundant components within a site.
Redundancy – A design practice of using multiple sources, devices, or connections so that no single point of failure will completely stop the flow of information.
Recovery Point Objective (RPO) – The point in time to which a firm must recover data as defined by the organization. In other words, the RPO is what an organization determines is an “acceptable loss” in a disaster situation. The RPO dictates which replication method will be required (such as nightly backups, snapshots, continuous replication). For example, for some organizations the RPO might be the loss of one hour’s worth of data.
Recovery Time Objective (RTO) – The duration of time and service level within which a business process must be restored after a disruption to avoid unacceptable losses. RTO begins when a disaster hits and does not end until all systems are up and running.
Production or Primary Site – In the context of a production and recovery site, the production site contains the original infrastructure and data. It is the site that is typically in use during normal operations.
Recovery or DR Site – A site that provides a secondary instance or replica of your IT environment and infrastructure. This site provides equivalent resources and is activated when the production site becomes unavailable.
Remote Site – A site that provides a secondary instance or replica of your IT environment—without physical desks and office infrastructure—that your organization’s employees can securely access and use remotely, through standard Internet connections from anywhere.
Cold Site – A site that is equipped with appropriate infrastructure components with adequate space that allows for the installation or buildout of a set of systems of services by the key staff required to resume business operations.
Pilot Light – The term pilot light refers to a small flame that is always lit in devices such as gas-powered heaters and can be used to start the devices quickly when required. Relative to disaster recovery, a pilot-light environment contains all the core components of a distinct system or service, that is adequately maintained and regularly updated. The implementation is always on and is built to functional equivalency of the production site. This implementation allows you to restore and scale the system quickly and efficiently.
Multiple Site – A system or service implemented in multiple locations, where the implementation provides one-for-one functionality of the other location in the event of an outage of any given site.
Mission Critical – A computer system or application that is essential to the functioning of your business and its processes.
SDDC Infrastructure – A Software based platform being leveraged as an infrastructure platform. Software-defined architecture can be deployed in your data center as a private cloud or off-site, using secure infrastructure-as-a-service (IaaS) operated by a certified partners. Most companies choose a hybrid combination of on-premises and IaaS platforms. Not all SDDC platforms have been certified for use with Horizon.
Additional Resources
To learn more about End User Computing solutions, visit Tech Zone, your fastest path to understanding, evaluating, and deploying EUC products.
Changelog
The following updates were made to this guide.
| Date | Description of Changes |
| 2024-05-15 | Updated for Omnissa docs, KB, and Tech Zone links |
| 2020-04-19 | Initial publication |
Authors and Contributors
This guide was written by:
- Graeme Gordon, Senior Staff Architect, Omnissa.
- Caroline Arakelian, Senior Technical Marketing Manager, Omnissa.
- Chris Halstead, Staff Architect, Omnissa.
- Hilko Lantinga, Staff Engineer, Omnissa.
- Jim Yanik, Senior Manager, Omnissa.
- Josh Spencer, Senior Product Line Manager, Omnissa.
- Rick Terlep, Senior Architect, Omnissa.
Feedback
Your feedback is valuable. To comment on this paper, either use the feedback button or contact us at tech_content_feedback@omnissa.com.